INTELIGÊNCIA ARTIFICIAL E COMPUTAÇÃO COGNITIVA EM UNIDADES DE INFORMAÇÃO
conceitos e experiências
Bárbara Coelho Neves[1]
Universidade Federal da Bahia.
babi.coelho7@gmail.com
______________________________
Resumo
Este artigo trata da inteligência artificial, com ênfase na computação cognitiva, como uma problemática contemporânea no contexto da cibercultura. Teve como objetivo investigar na literatura científica os principais aspectos da computação cognitiva em unidades de informação. Procurou levantar as perspectivas da computação cognitiva em unidades de informação e mapear como essas unidades têm utilizado (ou podem utilizar) a inteligência artificial em suas atividades e interação com o usuário. A metodologia utilizada se inscreve como pesquisa bibliográfica. Reflete com ênfase, principalmente, em outras leituras a partir do levantamento bibliográfico realizado na base de dados Ebsco e na Brapci, com recorte de 2009 a 2019. Foi realizada uma análise do discurso simples e a categorização dos assuntos dos artigos a partir das abordagens teóricas do ponto de vista da cibercultura. Destaca como resultado as principais definições encontradas na literatura, um case empírico que está sendo desenvolvido pela autoria deste artigo, a abordagem teórica com base na cibercultura, as perspectivas e aplicações dos artigos investigados. Finalmente se considera que a literatura sobre computação cognitiva trata da biblioteca e do bibliotecário no contexto contemporâneo. Os artigos são predominantes estrangeiros, na sua maioria são populistas tecnocráticos, possuem abordagens qualitativas e se referem a computação cognitiva como inteligência artificial.
Palavras-chave: Computação cognitiva. Inteligência Artificial. Unidades de Informação. Biblioteca. Aplicação.
ARTIFICIAL INTELLIGENCE AND COGNITIVE COMPUTING IN INFORMATION UNITS
concepts and experiences
Abstract
This article deals with cognitive computing as a contemporary problem in the context of cyberculture. It aimed to investigate in the scientific literature the main aspects of cognitive computing in information units. It sought to raise the perspectives of cognitive computing on information units and map how these units have used (or can use) artificial intelligence and or machine learning in their activities and interaction with the user. The methodology used is inscribed as bibliographic research. It intends to reflect with emphasis, mainly, on other readings from the bibliographic survey carried out in the database Ebsco and Brapci, with cut from 2009 to 2019. It highlights as result the main definitions found in the literature, an empirical case that is being developed by author of this article, the theoretical approach based on cyberculture, the perspectives and applications of the investigated articles. Finally it is considered that the literature on cognitive computing deals with the library and the librarian. Articles are predominantly foreign, mostly technocratic populists, have qualitative approaches, and refer to cognitive computing as artificial intelligence.
Keywords: Cognitive computing. Artificial intelligence. Information Units. Library. Application.
1 INTRODUÇÃO
Os avanços transcendentes no espaço digital é o que alguns tem chamado de a Quarta Revolução Industrial caracterizada pela integração do físico, do digital e do biológico. Exemplos que antes só eram possíveis na seara da ficção, hoje fazem parte do cotidiano da maioria das pessoas e incluem aprendizado de máquina autônoma, nanotecnologia, biotecnologia, Internet das coisas (IoT), impressão 3D, robótica, veículos autônomos, dentre outros.
A Inteligência Artificial (IA) foi mal compreendida ao longo dos anos, em parte porque as pessoas realmente não entendem do que se trata a IA, ou mesmo o que ela deve e pode realizar. Uma parte significativa do problema é que filmes, programas de televisão e livros conspiraram para dar falsas esperanças quanto ao que a IA realizará. Além disso, a tendência humana de antropomorfizar (dar características humanas) à tecnologia faz parecer que a IA deve fazer mais do que realmente ela pode executar.
Na Ciência da Informação já é hora de começarmos a discutir mais verticalmente a respeito da Computação Cognitiva (CC) e, acreditamos, que toda reflexão é bem vinda quando se trata de novas tecnologias no contexto social. No campo das unidades de informação não é diferente. O uso de dispositivos inteligentes, IA e da computação cognitiva nos espaços de construção do conhecimento vem avançando paulatinamente, proporcionando novas formas de interação com os sujeitos.
Não é de agora que as tecnologias digitais de informação e comunicação (TDIC) vêm desempenhando um papel marcante no contexto das unidades de informação. A área de Educação vem sendo continuamente influenciada em decorrência do crescente desenvolvimento e aplicação das tecnologias digitais em inúmeros processos educacionais e as unidades de informação tendem à acompanhar este movimento.
A CC é uma disciplina que integra conceitos da neurobiologia, da psicologia cognitiva, da ciência da informação e da inteligência artificial. Considerando a classificação da Associação Nacional de Pós-Graduação e Pesquisa em Educação (ANPED), o campo das discussões que envolvem tal temática dialoga com os elementos conceituais no eixo da Educação e Comunicação e de acordo com a Associação Nacional de Pesquisa e Pós-Graduação em Ciência da Informação (Ancib) no eixo que trata de Informação e Tecnologia.
Desse modo, este texto procurou responder o seguinte questionamento: como a literatura científica internacional e brasileira tem abordado a computação cognitiva nas unidades de informação. Para tanto o objetivo é investigar na literatura científica os principais aspectos da computação cognitiva em unidades de informação. Especificamente levantar as perspectivas da computação cognitiva em unidades de informação e mapear como essas unidades têm utilizado (ou podem utilizar) a inteligência artificial e ou aprendizado de máquina em suas atividades e interação com o usuário.
É imprescindível o uso dos recursos tecnológicos para facilitar o acesso à informação, assim como para colaborar com a vida dos acadêmicos, uma vez que o acervo disponível online reduz custos com a reprodução do material para o pesquisador e ainda contribui com o resultado da qualidade da pesquisa visto que dá acesso às matérias de interesse sem ônus para o usuário (LOPES; SOUZA, 2019).
Entende-se que a computação cognitiva é uma problemática contemporânea no contexto da cibercultura e que se enquadra nos esclarecimentos pronunciados por Marcuse (1998), ainda na década de 1940, no tocante dos fundamentos da teoria social crítica da tecnologia. Sendo em sua ótica, a tecnologia é um processo social e que se relaciona de forma dialética com algo não técnico (RUDIGER, 2016). Nessa perspectiva a compreensão é que os domínios da cibercultura, computadores e celulares, não são controlados pela classe política e pelas elites empresariais, mas pela força do mercado e sua mutável dinâmica. Dito isto, esse texto se encontra na linha do cibercriticismo.
Como metodologia este trabalho se inscreve como pesquisa bibliográfica. Pretende refletir, principalmente, com base em outras leituras a partir do levantamento bibliográfico realizado no Host da Ebsco e na Brapci. Utilizou-se a seguinte estratégia de recuperação de publicações: Thesauros Eric = (Cognitive Computing) and (Information) and (Science) or (Library) and (Artificial Intelligence) and (User).
O recorte temporal delimitado foi de 2009 a 2019. A escolha deste período recente está atrelada ao fato de que gostaríamos de problematizar as questões ligadas a computação cognitiva a partir do lançamento da plataforma Blumix (Watson da IBM) e dos sistemas cognitivos, a exemplo do TensorFlow.
Os artigos selecionados foram utilizados para elaboração desse texto de revisão de literatura. Atendendo esta estratégia, selecionamos os artigos de periódicos internacionais publicados com fator de impacto, ou com qualificação no caso dos periódicos brasileiros. Foi realizada uma análise do discurso simples e a categorização dos assuntos dos artigos a partir das abordagens teóricas do ponto de vista da cibercultura.
Com relação a verificações de credibilidade, adotamos procedimento similar à maioria dos outros estudos qualitativos. Ou seja, propositadamente construímos a verificação dos descritores a partir do Thesauro da Ciência da Informação disponível pelo Instituto Brasileiro de Informação em Ciência e Tecnologia (PINHEIRO; FERREZ, 2014), visando aumentar a insuspeição de nossas coletas de dados no conteúdo dos textos selecionados e análises de conteúdo simples para evitar “armadilhas” ou descuidos enquanto interpretamos os dados.
Esse artigo, além de tratar de alguns dos principais conceitos em torno da computação cognitiva, apresenta como case empírico um experimento, em fase de implementação, que visa investigar o uso da computação cognitiva em um Laboratório da Universidade Federal da Bahia.
2 Computação Cognitiva
A computação cognitiva é o que se tem de mais avançado em tecnologia computacional e que se expande conforme são realizados avanços no Big Data, na Internet das Coisas (IoT), em Machine learning e na inteligência artificial. Ela permite realizar análises de dados apuradas, gerando informações com alto nível de complexidade do ponto de vista da linguagem, aprendizado e interações com os sujeitos integrantes.
Os avanços do Big Data associados à inteligência artificial (AI) têm desvendado novos cenários, principalmente para suporte às atividades interativas com usuários, auxiliando de forma ativa segmentos da sociedade. A IA tornou-se um tópico de debate acalorado para muitas profissões (HILT, 2017).
A computação cognitiva é um campo que abrange áreas como ciência da computação, ciência da informação, cognição e inteligência no sentido de investigar as estruturas e os processos internos componentes do processamento de informações do cérebro e do funcionamento da inteligência natural (WANG, et al., 2010).
Do mesmo modo que a inteligência humana possui variações e tipos específicos, a inteligência artificial também está subdividida em domínios, conforme é possível perceber na figura a seguir:
|
Figura 1 – Domínios da Inteligência Artificial. |
|
|
|
Fonte: Alvear (2018). |
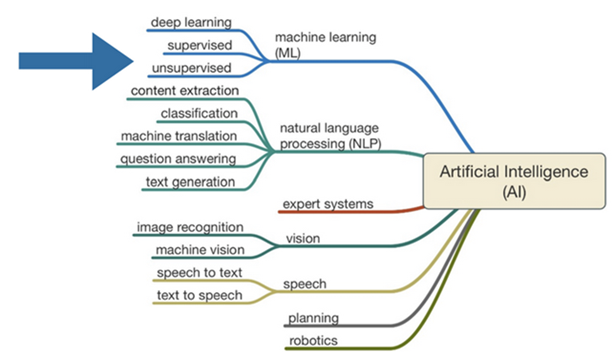
Conforme Mueller e Massaron (2018), o primeiro conceito que é importante entender é que a IA realmente não tem nada a ver com a inteligência humana. Sim, algumas IA são modeladas para simular a inteligência humana, mas é isso: uma simulação. Ao pensar em IA, observe uma interação entre a busca de objetivos, o processamento de dados usado para atingir esse objetivo e a aquisição de dados usada para melhor entender o objetivo. A IA se baseia em algoritmos para alcançar um resultado que pode ou não ter algo a ver com objetivos humanos ou métodos para atingir esses objetivos.
A Computação Cognitiva (conhecida como aprendizado de máquina, processamento de linguagem natural) pode ser também um novo hardware e/ou software para melhorar a tomada de decisão humana, imitando o cérebro humano (ELBECK, 2018). De forma similar, o aprendizado de máquina é um aspecto intrínseco da IA que permite que os algoritmos melhorem através do autoaprendizado a partir de dados sem qualquer intervenção humana (HILT, 2017).
De forma sucinta, a computação cognitiva se refere a computadores executarem ou emularem ações baseadas em aspectos cognitivos como seres humanos fazem (NEVES, 2018). Na perspectiva da computação cognitiva, os computadores vão para além dos cálculos avançados e processamento de dados, pois eles são capazes de processar, perceber e adquirir conhecimento. Os algoritmos elaborados para respostas em computação cognitiva são capazes de indexar, classificar, fazer edição, síntese de voz e fornecer respostas automáticas, dentre outras funções (NEVES, 2019). O sistema cognitivo permite a síntese de resposta autônoma que aprende a responder proporcionando o engajamento com quem interage.
|
Figura 2 – Deep Learning – aprendizado profundo |
|
|
|
Fonte: Muelle e Massaron (2018). |
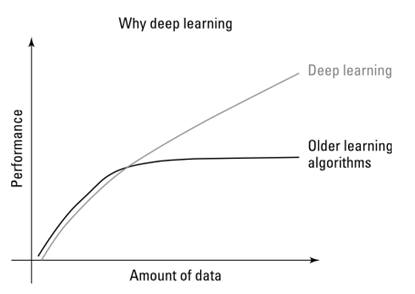
Os algoritmos e a IA mudaram o jogo de dados e os modelos de negócios. Os algoritmos de IA tentaram diferentes abordagens ao longo do desenvolvimento computacional, passando de algoritmos simples para o raciocínio simbólico baseado na lógica e depois para sistemas especialistas (MUELLE; MASSARON, 2018). Na contemporaneidade, eles podem formar verdadeiras redes neurais artificiais. Esse tipo de rede neural quando mais madura é denominada de Deep Learning ou aprendizado profundo. Os dados deixaram de ser apenas a matéria prima que alimenta a solução para protagonizarem como artesãos da própria solução, como mostra a Figura 2. Nesse contexto, com as atuais soluções de IA, mais dados quer dizer mais potencial de inteligência.
A área de Saúde tem sido pioneira no uso da Computação Cognitiva. Entende-se que os cases de aplicações neste campo podem fornecer caminhos para testes protótipos nas unidades de informação. No contexto da Saúde, sistemas de IA, como o IBM Watson, usam os dados individuais de saúde de um paciente - incluindo informações genéticas - com a riqueza de material disponível em bancos de dados públicos, livros didáticos e periódicos para ajudar a criar tratamentos mais personalizados (HILT, 2017).
2.1 Principais definições encontradas na literatura sobre computação cognitiva
Achou-se conveniente apresentar os principais assuntos ligados à computação cognitiva por serem termos que serão constantemente mencionados neste texto.
Assistentes pessoais de IA – Os assistentes pessoais de IA foram desenvolvidos para facilitar a obtenção de informações todos os dias em celulares, computadores e em outros dispositivos inteligentes (WILLIAMS, 2019). Não é preciso abrir um navegador de internet e pesquisar para ter acesso a informações. Esses assistentes podem até tocar suas músicas favoritas no Apple Music. A Siri é instalada no iPhone no momento da compra, o que significa que boa parte dos usuários pesquisadores estão acostumados a usá-la. Essa é a experiência que os usuários integrantes desejam quando estão procurando informações na biblioteca. Alguns exemplos de assistentes de grandes players com tecnologia IA: Amazon (Alexa), Apple (Siri), Microsoft (Cortana) e Google (Google Assistant).
Chatbot - De acordo com Bohle (2018), trata-se de é um programa de computador projetado para interagir com as pessoas emulando de perto a conversação humana, como idealizado no Teste de Turing para Inteligência Artificial. São usados na computação cognitiva para desenvolver interações por meio de diálogos sonoros, imagéticos e de texto.
Machine Learning (Aprendizado de máquina) – Aprendizado de máquina é o uso de “[...] programas de computador e algoritmos que podem extrair / derivar significado e padrões de dados” (BOURG apud BOMAN, 2019, p.10). O aprendizado de máquina é mais ou menos definido como um subconjunto de IA, mas nesse artigo será dado preferência ao termo computação cognitiva.
Artificial intelligence (inteligência artificial) - De acordo com o Dicionário Oxford, a inteligência artificial é a capacidade de computadores ou outras máquinas de exibir ou simular um comportamento inteligente. Na literatura científica, encontra-se mais uma distinção entre IA Geral, IA Estreita e algo chamado de Aprendizado de Máquina (FINLEY, 2019). A IA geral é algo parecido com a ficção científica, ou seja, uma inteligência artificial que aprende a aprender. A AI geral é capaz de generalizar o que aprendeu e aplicar esse conhecimento a um caso diferente. Nesse contexto é retirado o ponto de vista limitado de quem programa o programa. Já a IA específica é mais fácil de entender porque é a que se interage no dia-a-dia. É o que impulsiona essas pequenas acelerações que ajudam a fazer as coisas mais rápido todos os dias.
NLTK – É o kit de ferramentas de linguagem natural. O NLTK oferece módulos capazes de processar gramáticas em diversos formalismos e construir parsers por meio dos quais podemos analisar sentenças automaticamente, representando suas estruturas sob a forma de árvores (ALENCAR, 2012). São scripts em Python e estão intimamente integrados em um ILS por meio de webhooks e também chamadas de Application Programming Interface (API) que significa em tradução para o português "Interface de Programação de Aplicativos". É o NLTK permite a integração entre o processamento e a análise automática de sentenças em uma API que interpreta linguagem natural.
API – Já as API são as aplicações que fornecem serviços. API é um conjunto de rotinas e padrões de programação para acesso a um aplicativo de software, por exemplo um Chatbot precisa utilizar a API conversação. São extremamente importantes para executar as funções na computação cognitiva.
2.2 Learning Analytics e a Curadoria Digital
A área de Learning Analytics (LA) tem como objetivo melhorar os processos de ensino e aprendizagem através da análise de dados em larga escala e de maneira sistematizada, proporcionando auxílio em atividades de avaliação, compreensão de problemas e planejamento de intervenções (SIEMENS; BAKER, 2012).
Um dos principais campos que colaboram com a computação cognitiva, é a Curadoria Digital. Esse tipo de curadoria visa melhorar um conjunto de dados e processos operacionais e estratégicos. Siebra et al. (2013, não paginado) defendem que Curadoria Digital emerge dos estudos de Repositórios Digitais, como
[...] uma área de pesquisa e prática interdisciplinar que reflete uma abordagem holística para o gerenciamento do objeto digital e inclui atividades que abrangem todo o ciclo de vida desse objeto. De acordo com o Digital Curation Center (DCC), a curadoria digital exprime a ideia de manter e agregar valor à informação digital, tanto para uso atual quanto futuro e envolve a gestão ativa e a preservação de recursos digitais durante todo o ciclo de vida do dado digital, enquanto houver interesse do mundo acadêmico e científico. A preservação digital passa, então, a ser é entendida como uma etapa no âmbito desse ciclo.
Nesse sentido surge a curadoria digital, com vistas ao gerenciamento do objeto digital contendo atividades que abarcam todo o ciclo de vida desse objeto, com o intuito que ela continue acessível e se consiga recuperar por quem dele precise.
Conforme explicam Rosenbaum (2011) e Beiguelman (2011), o crescimento da pertinência de curadoria de informação ao gigantesco volume de dados na web, abrangendo os mecanismos de busca, os sites de redes sociais entre outras; o que apresenta a administração de uma grande quantidade de dados na Internet e em Internet, levando em conta um conceito bastante conhecido, o de curadoria, que na atualidade é ajustado ao entorno digital. Nesse contexto, a atuação da “curadoria digital” é um termo que engloba distintas terminologias e níveis de desempenho como: “curadoria de informação”, “curadoria de conteúdo”, “curadoria de conhecimento” e “curadoria de dados”, que na maioria dos casos põe como protagonista os seres humanos, os quais têm a capacidade de filtrar informações e reorganizá-las para uma vasta quantidade de usuários (ROSENBAUM, 2011).
Para Rosenbaum (2011), a grande quantidade de informação promove a busca de material de qualidade, reflexivo, filtrado e organizado pelos humanos, o qual seja investigado por periodistas, e que seja intelectualmente relacionado. Justamente é isso a curadoria digital, é a capacidade de um sistema ou um ser humano para encontrar, organizar, filtrar e dar valor, relevância e significância à informação de um assunto específico que vem de diferentes fontes como: mídias digitais, ferramentas de comunicação, redes sociais, entre outras.
De acordo com Campos (2018), o alinhamento dos campos de Learning Analytics e Computação Cognitiva se mostra favorável aos processos de personalização na educação, sobretudo pelo uso de abordagens de ensino e aprendizagem como as metodologias ativas. Além disso, vislumbra-se que plataformas como Watson da IBM tem um potencial interativo ainda pouco explorado na área da Ciência da Informação. Por isso justifica-se a necessidade e importância de testa-la no campo das habilidades não cognitivas, utilizando a metodologia de valores humanos ainda inédita no Brasil.
Desde 2016 que a IBM tem investido fortemente em países como a Coreia do Sul. Segundo Taft (2016), o vice-presidente sênior da IBM Cloud, Robert LeBranc, informou que seu novo centro de dados coreano apoiará o desenvolvimento de soluções de computação cognitiva e inteligência artificial para promover o uso da plataforma de desenvolvimento de nuvem Bluemix da IBM. A Bluemix é uma plataforma que, dentre outras coisas, permite acesso a bots e a computação cognitiva desenvolvida com base em sofisticados algoritmos de IA e APIs.
3 O que o futuro reserva para o bibliotecário no advento da computação cognitiva?
A história das máquinas que substituem o trabalho humano tem sido uma situação agridoce desde a revolução industrial. De um lado, as pessoas têm poupado ou evitado cada vez mais tarefas inconvenientes, difíceis, repetitivas e perigosas. Por outro lado, perde-se continuamente as habilidades tradicionais e a habilidade de alto nível desenvolvidas ao longo do ciclo de desenvolvimento das gerações. De acordo com Nolin (2015) vale salientar que toda vez que novas tecnologias seguras e baratas permitem que uma máquina faça o trabalho de 20 pessoas, teme-se a extinção de postos de trabalho. No entanto, continua o autor com o apoio de Fingar (2015) que, como ao longo da história se tem repetidas vezes experimentado esse mesmo padrão, tende-se a se sentir confiante.
Um novo aplicativo baseado em dispositivos móveis, como o Uber, pode em poucos meses causar estragos em um mercado de táxi robusto, levando a greves em junho de 2014 em várias cidades europeias como Londres, Paris e Madri. De fato, recentemente foram publicados vários livros semi-populares que argumentam vigorosamente que essa destruição particular do trabalho antigo e a criação de novos empregos são diferentes (NOLIN, 2015, p. 3, tradução nossa).
O processo de transformação digital não é exclusividade das unidades de informação. Esse processo de modificações está acontecendo em todas as áreas, campos de atuação e atividades. É só observar o exemplo dos caminhoneiros, que serão inevitavelmente substituídos por caminhões autônomos. Esse aspecto da transformação digital representa, no mínimo, que todos envolvidos neste movimento precisarão adquirir novas habilidades e novos conhecimentos, e as bibliotecas precisam se colocar neste movimento como um “nicho” que pode ajudar a fornecer essa educação para a sociedade.
Não é que se seja exclusivamente otimista sobre o movimento de transformação digital e a inserção cada vez mais eminente da inteligência artificial nas unidades de informação. Entretanto, os artigos investigados para produzir este texto, se mostraram numa perspectiva positiva com relação ao futuro do bibliotecário frente ao advento da computação cognitiva.
Além das habilidades genéricas de gerenciar informações e serviços, o papel do bibliotecário tem ficado a cada dia mais complexo. Embora esse profissional continue a desenvolver suas atividades em torno de encontrar informações específicas para seus usuários, essa ação pode levar menos tempo com a implementação de tecnologias cada vez mais rápida e interativas. Defende-se como resultado, que essa mudança pode significar que os bibliotecários estarão mais ocupados do que nunca, porque estão assumindo outras tarefas para aumentar seu valor para as instituições e organizações que os empregam (HILT, 2017).
De acordo com alguns autores (HILT, 2017; ARLITSCH; NEWELL, 2017) os papéis em expansão dos profissionais de informação jurídica atuais tendem a se concentrar na gestão do conhecimento, no suporte ao cliente transformador e no trabalho de desenvolvimento de negócios. Os profissionais da informação podem assumir o papel de liderança na captura e monitoramento de dados sobre a mudança do fluxo de tarefas, examinando questões como: Como os processos podem ser padronizados? o que poderia ser feito para reduzir ou eliminar a repetição? como a comunicação pode ser melhorada dentro da equipe e/ou com os usuários; e como poderiam ser delegadas as tarefas e reduzir custos?
Conforme as máquinas começam a assumir cada vez mais significativa parcela do trabalho de "pensamento" humano, acredita-se que seja importante que as bibliotecas preparem sua própria equipe e se tornem centros de educação continuada para suas comunidades de atendimento. Segundo Arlitsch e Newell (2017, p. 795, tradução própria) as “[...]bibliotecas, tanto acadêmicas quanto públicas, há tempos se posicionam como lugares para aprendizagem ao longo da vida, e essa posição representa uma oportunidade para ser aproveitada.”
3.1 Abordagem da literatura científica internacional e brasileira sobre a computação cognitiva nas unidades de informação
Foram mapeados nove artigos no Host da EBSCO e um na BRAPCI. As estratégias de pesquisa nestas bases foram aquelas já sinalizadas na introdução. Para extrair as informações e responder os questionamentos dos objetivos geral e específicos, realizou-se uma análise de conteúdo simples (SANTOS, 2003; MAY, 2004; MUELLER, 2007). Desse modo, trata-se de pesquisa qualitativa, com metodologia de pesquisa bibliográfica e método de análise dialética, considerando a ótica de interpretações na perspectiva do cibercriticismo (RUDIGER, 2016).
Assim como a inteligência artificial, a computação cognitiva é um tema polêmico no contexto das Ciências Sociais Aplicadas e Humanidades, pois estas grandes áreas lidam com sujeitos e sua interação com a dinâmica da sociedade. Identifica-se uma polêmica sobre a técnica no contexto digital. Dito isto, procurou-se identificar nos artigos investigados suas abordagens teóricas do ponto de vista da cibercultura:
a) Populistas – Os populistas tecnocráticos são os que defendem as virtudes morais, políticas e econômicas da tecnologia na sociedade. São coletivos de autores, pesquisadores e sobretudo profissionais ligados aos negócios de informática e telecomunicações.
b) Conservadores – São tidos como conservadores midiáticos acadêmicos literários ou militantes com formação mais tradicional. São os acusadores do fenômeno ou movimento de todo o resultado da tecnologia na sociedade.
c) Criticistas – São aqueles interessados em refletir sobre as conexões entre todos os aspectos da cibercultura e o poder (economia, política, social) e seus atores (mídia, escola, etc.,) considerando os problemas e desafios que isso “[...] acarreta para o sujeito social, especial a figura do indivíduo” (RUDGER, 2016, p.26), como é o caso por exemplo nesse artigo a biblioteca e o bibliotecário.
O primeiro artigo analisado “Thriving in the age of accelerations: a brief look at the societal effects of artificial intelligence and the opportunities for libraries” apresenta uma perspectiva criticista. Trata do aumento das velocidades de rede, a disponibilidade de big data e como as técnicas de aprendizado de máquina aceleraram o desenvolvimento da inteligência artificial. De acordo com os autores Arlitsch e Newell (2017, p. 790, tradução própria) isso “[...] promete mudar dramaticamente muitas instituições, incluindo bibliotecas”. Este artigo oferece algumas reflexões sobre os efeitos da automação sobre o emprego, as consequências sociais e políticas e as ameaças e oportunidades para bibliotecas escolares, universitárias e públicas. Como é possível perceber esta publicação traz uma abordagem qualitativa e começa sua problematização com a seguinte questão: A tecnologia cria ou destrói empregos?
Dois dos artigos selecionados tratavam do uso da computação cognitiva em bibliotecas jurídicas. O primeiro “2018: Uma Odisseia de Pesquisa Jurídica: Inteligência Artificial como Disruptor” aponta que a computação cognitiva tem o poder de tornar a pesquisa jurídica mais eficiente, mas não elimina a necessidade de ensinar os estudantes de direito a somar processos e estratégias legais de pesquisa. Destaca que os bibliotecários jurídicos também devem instruir o uso responsável da inteligência artificial, procurando entender os funcionamentos de sua face algorítmica, como indivíduo que tem o dever de se apropriar da competência tecnológica, para evitar negligenciar armadilhas e a prática não autorizada das leis. Baker (2018) coloca os bibliotecários como experts capazes de estimular nos usuários competências informacionais para interagir com a inteligência artificial. Com base na discussão desse artigo, enquadrou-se na perspectiva populista tecnocrático, com abordagem qualitativa.
O segundo artigo intitulado “What Does the Future Hold for the Law Librarian in the Advent of Artificial Intelligence” aborda como a tecnologia está transformando o trabalho dos profissionais da informação à medida que os métodos de recuperação de informações continuam a evoluir. Segundo Hilt (2017) a inteligência artificial está sendo incorporada em muitas práticas jurídicas para fins de pesquisa, descoberta digital e análise da documentação. Embora a profissão legal esteja nos estágios iniciais de incorporação da tecnologia IA, não é certo se uma aplicação aprimorada por inteligência artificial poderá conduzir pesquisas jurídicas de forma inteligente, eliminando a necessidade de advogados e bibliotecários se envolverem em atividades de pesquisa. Com base nesta reflexão qualitativa de Hilt (2017) foi possível enquadra este texto na perspectiva do cibercriticismo.
Outro artigo também mapeado na perspectiva populista foi o intitulado “An overview of the NFAIS 2014 Annual Conference – Giving Voice to Content: Re-Envisioning the Business of Information”. Nele Lawlor (2014) apresenta o conteúdo tratado como destaques da Conferência Anual da NFAIS de 2014, que foi realizada em Filadélfia, PA, de 23 a 25 de fevereiro de 2014. O objetivo da conferência foi examinar as oportunidades oferecidas pelas atuais tecnologias de Big Data (métricas, análises, mineração de dados, visualização, vinculação, etc.) e desafiar provedores de conteúdo e bibliotecários a tentarem se libertar das restrições e vieses do passado. Lawlor apresenta o conteúdo da conferência de forma otimista e pede que os bibliotecários imaginem como seriam seus produtos, serviços e modelos de negócios se essas tecnologias fossem totalmente utilizadas nas bibliotecas.
O artigo “Unleashing the Power of Data Through Organization: Structure and Connections for Meaning, Learning and Discovery” não fala diretamente das bibliotecas, mas sim de como os profissionais de informação e unidades de informação que lidam com a aplicação da organização do conhecimento em bases de IA para respostas a perguntas e sistemas cognitivos, bases para extração de informações de texto ou multimídia, dados lineares, big data e dados analíticos, registros digitais, influência diagramas (mapas causais), modelos de sistemas dinâmicos, diagramas de processos, mapas conceituais e outros diagramas de enlace, sistemas de informação em organizações, organização de conhecimento para compreensão e aprendizagem, e transferência de conhecimento entre domínios. Soergel (2015) argumenta a necessidade dos profissionais de informação, nesses novos contextos, precisam ir além para uma representação mais poderosa usando entidades e relacionamentos de múltiplas vias, mas não atributos. Diante da maneira como a tecnologia e o novo cenário de computação cognitiva é tratado no texto, este foi enquadrado na perspectiva populista tecnocrático com abordagem qualitativa das suas análises.
O artigo “The Democratization of Artificial Intelligence: One Library’s Approach” relata como a Biblioteca Pública de Frisco, no Texas, desenvolveu um programa de ensino e empréstimo de tecnologia em torno da inteligência artificial. Segundo Finley (2019), a biblioteca criou kits que os usuários podem levar para casa e usar para explorar a IA através de uma abordagem prática. A distinção entre IA geral, computação cognitiva e aprendizado de máquina é discutida. A aprendizagem de máquina é o foco dos estudos de Finley (2019) na Biblioteca Pública Frisco devido, segundo ele, a dois motivos principais: a) É o que foi disponibilizado através de ferramentas gratuitas como os recursos abertos de IA do Google; e b) porque isso torna a IA alcançável em um ambiente de biblioteca. Os elementos tratados no artigo sob abordagem qualitativa apontam para a perspectiva populista tecnocrática.
Em “Artificial Intelligence Assistants in the Library: Siri, Alexa, and Beyond” apresenta o uso dos assistentes pessoais de inteligência artificial nas bibliotecas. Williams (2019) relata sua experiência com a utilização dos assistentes com tecnologia IA introduzidos pela Apple (Siri), Amazon (Alexa), Apple (Siri), Microsoft (Cortana) e Google (Google Assistant) e como estes podem facilitam a busca de informações em nossas vidas diárias e em ambientes informacionais. Williams coloca que esses assistentes podem substituir a necessidade de interação com os profissionais da informação, conforme relata que é necessário que se [...]
Tenha em mente, porém, que os assistentes de IA foram desenvolvidos como produtos de consumo, não para bibliotecários. Mas uma consequência é de grande importância para os profissionais da informação [...] as pessoas não precisam mais visitar sua biblioteca local e obter assistência de um bibliotecário (WILLIAMS, 2019, p. 11, tradução nossa).
Com base nessa e em outras afirmações ao longo do texto, enquadra-se como conservadorismo midiático qualitativos do uso dos programas de assistentes pessoais. Conforme explica Rudger (2016, p. 37), “[...] os cuidados que devemos ter com ela (Internet) não podem ser separados da consideração das contigências políticas a que está submetida e dos seus usos sociais predominantes”. A internet não é neutra, porque seu uso e seu desempenho dependem de condições sociais determinadas.
“Plutchik: artificial intelligence chatbot for searching NCBI databases”, trata-se de um paper que aponta o uso dos chatbots no apoio às pesquisas em base de dados no Centro Nacional de Informações sobre Biotecnologia (NCBI) hospedadas pela Biblioteca Nacional de Medicina (NLM). Vale salientar que uma das bases deste projeto piloto é a PubMed. De acordo com seu autor, Bohle (2018), "Plutchik" é um exemplo de como as bibliotecas podem usar a inteligência artificial para permanecerem relevantes para os pesquisadores mais jovens, que estão acostumados com as tecnologias comerciais de IA móveis e virtuais, como Siri, Google Assistant, Cortana e Alexa. Identificou-se como abordagem a qualitativa e na perspectiva populista tecnocrática.
O artigo “An Exploration of Machine Learning in Libraries” ao abordar o aprendizado de máquina em bibliotecas, acrescenta que muitos projetos em potencial podem permitir uma abordagem de aprendizado de máquina nas unidades de informação. Segundo Boman (2019), o aprendizado de máquinas se trata de um desafio específico que está em fase de amadurecimento para bibliotecas com base em modelagem de tópicos. No artigo Boman defende que os aprimoramentos em aprendizado de máquina permitiram o que “[...]que os catalogadores forneçam serviços maiores aos seus usuários” (BOMAN, 2019: 25). Com base nessa e em outras afirmações, destaca-se o artigo como qualitativo e na perspectiva populista.
Como foi possível perceber, os artigos sobre computação cognitiva em unidades de informação, mapeados na Ebsco, em sua maioria possuem uma abordagem qualitativa e se inserem na perspectiva populista tecnocrática.
No contexto da literatura científica brasileira foram encontrados artigos científicos tratando de inteligência artificial na Ciência da Informação. Destaca-se o artigo de Martins (2010, p. 2) que discute “[...] as principais técnicas de IA utilizadas atualmente, por meio de embasamento conceitual e tecnológico”. Esse texto intitulado “Potenciais aplicações da Inteligência Artificial na Ciência da Informação” presenta vários possíveis usos da inteligência artificial pela Ciência da Informação na resolução de problemas atualmente difíceis de serem tratados tanto pelo processamento manual quanto automatizado. Martins (2010) vislumbra que a IA tem seu papel de destaque na distância que se estabelece entre o que o usuário realmente deseja e o que o sistema recupera. Uma das causas desta distância é a falta de habilidades informacionais do usuário frente ao uso da interface de busca.
3.2 Perspectivas e aplicações da computação cognitiva em unidades de informação
Com base na análise da literatura científica internacional, as maiores perspectivas da computação cognitiva em unidades de informação são a transformação do trabalho dos profissionais, melhoria do processamento de informações, o apoio à pesquisa, técnicas do aprendizado de máquina incorporados aos sistemas de automação, atuação dos profissionais como especialistas capazes de intermediar os usuários com a IA e a apropriação das ferramentas e recursos da computação cognitiva. Vale salientar que a maioria dos artigos que investigamos destacam a biblioteca como espaço dessas experiências e o bibliotecário como ator ativo dessas transformações.
Com relação às aplicações da computação cognitiva, a literatura também da maior ênfase à biblioteca. Segundo Boman (2019), a computação cognitiva pode ser utilizada na identificação de cabeçalhos de e-books. Nessa experiência o autor está testando o uso de linguagem natural com Phiton no Project Gutenberg da Biblioteca do Congresso.
De acordo com Martins (2010), interfaces inteligentes também podem se utilizar de mecanismos de IA. Atualmente o número de sistemas de informações digitais tem crescido a uma velocidade nunca imaginada, porém, cada um deles com uma interface para recuperação da informação gerada de maneira diferente (MARTINS, 2010).
Para Arlitsch e Newell (2017) e Boman (2019) é importante que as bibliotecas preparem sua própria equipe e se tornem centros de educação continuada para suas comunidades. Os autores entendem que a computação cognitiva, como parte da inteligência artificial, é uma oportunidade de reafirmar a nobreza da missão da biblioteca. As máquinas podem imitar a linguagem e algumas das qualidades humanas, mas por enquanto elas permanecem no domínio dos humanos. A confiança do público nas bibliotecas deve permanecer exclusivamente para oferecer assistência àqueles que desconfiam do governo, da mídia e dos especialistas acadêmicos.
Para Bohle (2018) e Williams (2019), as aplicações de recursos da computação cognitiva e de inteligência artificial podem servir de alternativas de interação e apoio à pesquisa dos usuários. Exemplo desse tipo de aplicação é o “Projeto Plutchik” que tem como objetivo criar um chatbot corporativo “empático” para pesquisar, recuperar, analisar e comunicar informações médicas e interagir com profissionais de saúde em linguagem natural e “voz” usando expressões faciais e gestos 3D. O “Project Plutchik” é o primeiro chatbot disponível ao público (sujeito a condições de licenciamento) para pesquisar dados das bases de dados do NCBI através dos códigos de Classificação Internacional de Doenças, Décima Revisão, Modificação Clínica (CID-10-CM) e recuperar a informação (BOHLE, 2018). Williams (2019) destaca a aplicação da computação cognitiva como apoio na estratégia de busca complexas para recuperação de informações eficazes e personalizadas em bancos de dados.
Destaca-se também no rol das aplicações, a biblioteca como espaço de construção do conhecimento frente a transformação digital. Esse é um aspecto que particularmente interessa a autoria deste artigo e que, certamente, se constitui a origem do desejo de realizar o estudo sobre este objeto “computação cognitiva em unidades de informação”. Nesse contexto, a biblioteca pode ser também entendida como espaço maker. Com kits disponibilizados pelo Google em Python e Machine Learning do Amazon Web Services (AWS), uma biblioteca pública do Texas tem disponibilizado empréstimo de faça você mesmo sua inteligência artificial e assim se colocando como formadora no uso da computação cognitiva.
O que está claro é que o mundo da IA já está sobre a sociedade. De acordo com Finley (2019), as bibliotecas públicas precisam estar bem posicionadas para ajudar a enfrentar o desafio de desenvolver a força de trabalho do futuro próximo e as unidades de informação precisam também promover ou apoiar formações com aulas de IA.
Martins (2010) e Soergel (2015) apontam que o processamento técnico das unidades de informação, com destaque para bibliotecas, e a automação também pode se beneficiar dos recursos da computação cognitiva. Pode ser empregada em sistemas que permitem a classificação automática de conteúdos, uma vez que para serem recuperados precisam de uma organização que seja tanto lógica quanto semanticamente coerente (MARTINS, 2010).
Também foi possível destacar aplicações da computação cognitiva no contexto da gestão da informação. Visando auxiliar na mineração de dados. A Conferência Anual da NFAIS de 2014, relatada por Lawlor (2014) apontou como a mineração de traços digitais, por meio de IA, pode melhorar a tomada de decisão política com traços digitais em grande escala, fornecendo insights extraídos dos dados de aparelhos celulares, por exemplo. Mineração de dados é o processo de explorar grandes quantidades de dados à procura de padrões consistentes, isso pode ser facilitado com o apoio da computação cognitiva.
A capacidade de levantar, reinventar ou criar novas camadas de conhecimento usando técnicas que associam inteligência artificial, computação cognitiva e big data (como mineração de dados, vinculação, análise e métricas) desafia os bibliotecários para garantir sua relevância em um mundo de informações digitais altamente competitivo. A questão que agora se insere é como começar a colocar em prática pois o futuro chegou com todas as “ficções” científicas.
4 Considerações Finais
Este artigo entende que as unidades de informação precisam adquirir habilidades quantitativas e analíticas para aprender o valor do Big Data, da inteligência artificial e da computação cognitiva e como essas novas tecnologias podem ser manipuladas, visualizadas e analisadas pelo bibliotecário. Em suma, deve-se continuar a encontrar maneiras de fazer as máquinas funcionarem em prol das unidades de informação.
O foco e a contribuição deste artigo foi investigar a perspectiva e aplicações da computação cognitiva no contexto das unidades de informação. O desafio é como incorporar essa inovação descontínua como um ativo benéfico para a Ciência da Informação. Para tanto teve como objetivo investigar na literatura científica os principais aspectos da computação cognitiva em unidades de informação. Especificamente, levantou-se as perspectivas da computação cognitiva em unidades de informação e mapeou-se como essas unidades têm utilizado (ou podem utilizar) a inteligência artificial e ou aprendizado de máquina em suas atividades e interação com o usuário. A maioria dos artigos encontrados tratam da biblioteca, são populistas tecnocráticos, possuem abordagens qualitativas no trato do objeto de sua análise e se referem a computação cognitiva como inteligência artificial.
O cenário de transformação digital deixa claro que nada será como agora. A entrega centrada em API, como um serviço, está transformando o consumo de serviços comerciais, assim como a nuvem transformou o modelo de consumo de tecnologia da informação (TI). Com as tendências e aplicações que estão alimentando a criação da era da computação cognitiva, as empresas, instituições e indivíduos enfrentam uma pressão significativa para alavancar a tecnologia e se diferenciar como nunca antes para se manterem necessários.
A porta para a inteligência artificial está aberta, a única questão que resta é: a biblioteca passa por ela?
Referências
ALENCAR, Leonel Figueiredo de. Donatus: uma interface amigável para o estudo da sintaxe formal utilizando a biblioteca em Python do NLTK. Alfa, rev. linguíst. (São José Rio Preto), São Paulo, v. 56, n. 2, p. 523‑555, dez. 2012. Disponível em: http://dx.doi.org/10.1590/S1981‑57942012000200008. Acesso em: 20 jan. 2020.
ALVEAR, Johanna Orellana. Arboles de decision y random forest. 2018.
ARLITSCH, Kenning; NEWELL, Bruce. Thriving in the age of accelerations: a brief look at the societal effects of artificial intelligence and the opportunities for libraries. Journal of Library Administration, v. 57, p. 789‑798. 2017. Disponível em: https://www.tandfonline.com/doi/abs/10.1080/01930826.2017.1362912. Acesso em: 2 ago. 2019.
BAKER, J. J. A legal research odyssey: artificial intelligence as disruptor. Law Library Journal, v. 110, n. 1, 2018. Disponível em: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2978703. Acesso em: 03 maio 2019.
BEIGUELMAN, G. Curadoria de informação. Palestra, USP, 2011. ENCONTRO COM O FUTURO – ECA- USP. São Paulo: USP, jun. 2011. Disponível em: http://www.slideshare.net/gbeiguelman/curadoria-informacao. Acesso em: 03 maio 2016.
BOMAN, C. An exploration of machine learning in libraries. Library Technology Reports, v. 55, n. 1, jan. 2029. Disponível em: https://www.questia.com/library/journal/1G1-569892809/an-exploration-of-machine-learning-in-libraries. Acesso em: 03 jan. 2020.
CAMPOS, A. Mapeamento de iniciativas de computação cognitiva e suas potencialidades em processos educacionais. In: SENID, 5., 2018, Passo Fundo. Anais [...]. Passo Fundo: Senid, v. 5, p. 1-10, 2018. Disponível em: https://www.upf.br/_uploads/Conteudo/senid/2018-artigos-resumidos/179278.pdf. Acesso em: 20 mar. 2020.
CASTANHA, R. C. G.; LIMA, L, de M.; MARTÍNEZ-ÁVILA, D. Análise do discurso sob a perspectiva bibliométrica nos estudos de Ciência da Informação no Brasil. Perspectivas em Ciência da Informação, Belo Horizonte, v. 22, n.1, p. 17-37, jan./mar., 2017. Disponível em: http://portaldeperiodicos.eci.ufmg.br/index.php/pci/article/view/2813/1840. Acesso em: 6 abr. 2019.
ELBECK, M. The fourth industrial revolution’s potential influence on marketing education. e-Journal of Business Education & Scholarship of Teaching, v. 12, n. 1, p. 112-119, 2018. Disponível: https://eric.ed.gov/?id=EJ1183303. Acesso: 6 abr. 2020.
FINGAR, P. Cognitive computing: a brief guide for game changers. Florida, Meghan-Kiffer Press, 2015.
FINLEY, T. The democratization of artificial intelligence: one library’s approach. Information technology & libraries, v. 38, n. 1, 2019. Disponível em: https://ejournals.bc.edu/index.php/ital/article/view/10974. Acesso em: 20 dez. 2019.
HILT, K. What does the future hold for the law librarian in the advent of artificial intelligence? The Canadian Journal of Information and Library Science: la revue canadienne des sciences de l’information et de bibliothe ́conomie, v. 41, n. 3, 2017. Disponível em: http://web-a-ebscohost.ez20.periodicos.capes.gov.br/ehost/. Acesso em: 2 ago. 2019.
LAWLOR, B. An overview of the NFAIS 2014 annual conference – giving voice to content: re-envisioning the business of information. Information Services & Use, v. 34, n. 1-2, p. 3‑15, 2014. Disponível em: https://dl.acm.org/doi/10.5555/3183947.3183948. Acesso em: 3 ago. 2019.
LOPES, A. S.; SOUZA, J. P. O acesso aos documentos com ou sem o uso da tecnologia da informação. LOGEION: Filosofia da informação, Rio de Janeiro, v. 5, n. 2, p. 72-85, mar./ago. 2019. Disponível em: http://revista.ibict.br/fiinf/article/view/4822/4200. Acesso em: 26 jun. 2020.
MAY, T. Pesquisa documental: escavações e evidencias. In: MAY, T. Pesquisa social: questões, métodos e processos. Porto Alegre: Artmed, 2004.
MARCUSE, H. Some Social Implications of Modern Technology. In: KELLNER, D. Technology, War, and Fascism. New York: Routledge, p. 39-66, 1998.
MARTINS, A.L. Potenciais aplicações da inteligência artificial na ciência da informação. Informação & Informação, v. 15, n. 1, p. 1‑16, jul./jun. 2010. Disponível em: http://www.uel.br/revistas/uel/index.php/informacao/issue/view/530. Acesso em: 20 jun. 2020.
MOHDA, D.S. et al. Cognitive computing. Communications of the ACM, v. 54, n. 8, p. 62-71, 2011. Disponível em: https://dl.acm.org/doi/fullHtml/10.1145/1978542.1978559. Acesso em: 20 maio 2019.
MUELLER, Suzana Pinheiro Machado. Métodos para a pesquisa em Ciência da Informação. Brasília: Thesaurus, 2007.
MUELLER, J.P.; MASSARON, L. Artificial Intelligence. New Jersey: John Wiley & Sons, 2018.
NEVES, B. C. Computação cognitiva: novas perspectiva para a ciência da informação. InfoHome. São Paulo, p. 1-3. dez, 2018. Disponível em: https://www.ofaj.com.br/colunas_conteudo.php?cod=1100. Acesso em: 10 jul. 2018.
NEVES, B. C. As perspectivas e aplicações da computação cognitiva em unidades de informação. In: ENCONTRO NACIONAL DE PEQUISA EM CIÊNCIA DA INFORMAÇÃO (ENANCIB), 20., 2019, Santa Catarina: UFSC. Anais […]. Disponível em: https://conferencias.ufsc.br/index.php/enancib/2019/paper/view/1421. Acesso em: 20 ago. 2019.
PINHEIRO, L. V. R.; FERREZ, H. D. Thesauro da Ciência da Informação. Brasília: IBICT, 2014. Disponível em: http://www.ibict.br/images/internas/TESAURO-COMPLETO-FINAL-COM-CAPA-_24102014.pdf. Acesso em: 20 abr. 2020.
ROSENBAUM, S. Curation nation: why the future of context is context. NY, McGraw Hill, 2011.
RÜDIGER, F. Teorias da cibercultura: as perspectivas, questões e autores. Porto Alegre: Editora Meridional, 2016.
SIEBRA, S. A. et al. Curadoria digital: além da questão da preservação digital. In: ENCONTRO NACIONAL DE PESQUISA EM CIÊNCIA DA INFORMAÇÃO (ENANCIB), 14, 2013. Santa Catarina: UFSC. Anais [...]. Florianópolis. Disponível em: http://enancib.sites.ufsc.br/index.php/enancib2013/XIVenancib/paper/viewFile/317/320. Acesso em: 30 abr. 2016.
SIEMENS, G.; BAKER, R. S. Learning analytics and educational data mining: towards communication and collaboration. In: PROCEEDINGS OF THE 2ND INTERNATIONAL CONFERENCE ON LEARNING ANALYTICS AND KNOWLEDGE. ACM, 2012. Disponível em: https://learningenvironmentsdesign.pressbooks.com/chapter/siemens-and-baker-learning-analytics-and-educational-data-mining-towards-communication-and-collaboration/. Acesso em: 20 mar. 2020.
SOERGEL, D. Unleashing the power of data through organization: structure and connections for meaning, learning and Discovery. Knowledge Organization, v. 42, n. 6, 2015. Disponível em: https://documents.pub/document/unleashing-the-power-of-data-through-organization-structure-and-connections.html. Acesso em: 20 mar. 2020.
NOLIN, J. Essay review: The future of the work we don't do. Information Research, v. 20, n. 4, dez. 2015. Disponível em: https://www.diva‑portal.org/smash/get/diva2:894210/FULLTEXT01.pdf. Acesso em: 20 mar. 2020.
SANTOS, Cássia T.; OSÓRIO, Fernando S. O Uso de Técnicas de Aprendizado de Máquina na Categorização de Documentos. In: CONFERÊNCIA LATINO AMERICANA DE INFORMÁTICA, 29., 2003, La Paz. Proceendigs... 2003.
TAFT, D. K. IBM launches new cloud data center in Korea. eWeek, 2016. Disponível em: http://web‑a‑ebscohost.ez20.periodicos.capes.gov.br/ehost/detail/detail?vid=11&sid=eb8c977d‑d94b‑49b9‑9486‑ed23540274ee%40sdc‑v‑sessmgr02&bdata=Jmxhbmc9cHQtYnImc2l0ZT1laG9zdC1saXZl#AN=117744020&db=aph. Acesso em: 3 de ago. 2019.
WILLIAMS, R. Assistentes de inteligência artificial na biblioteca: Siri, Alexa e Beyond. Online Searcher, maio/jun. 2019.