CÂMARAS DE ECO POLÍTICAS DURANTE OS ATOS ANTIDEMOCRÁTICOS:
topologia de interação no Twitter/X
William Tsuyoshi Matsuda[1]
Universidade Federal de São Carlos
william.matsuda@estudante.ufscar.br
Helena de Medeiros Caseli[2]
Universidade Federal de São Carlos
Alan Demetrius Baria Valejo[3]
Universidade Federal de São Carlos
Sylvia Iasulaitis[4]
Universidade Federal de São Carlos
______________________________
Resumo
A formação de câmaras de eco (echo chambers) consiste em um fenômeno no qual os usuários são frequentemente expostos a pontos de vista que reforçam suas crenças, dificultando a exposição a perspectivas divergentes. Enquanto sabe-se do surgimento e da disseminação das câmaras de eco que se formam em comunidades online, a identificação automática e compreensão deste fenômeno surge como uma importante ferramenta para auxiliar a investigação das suas implicações na esfera política e na democracia. O objetivo deste artigo é a investigação, implementação e avaliação de métodos para a detecção de câmaras de eco em redes sociais digitais durante os Atos Antidemocráticos de 8 de Janeiro de 2023. A investigação desse fenômeno foi realizada por meio da combinação de modelagem de comunidades baseada em redes, da análise de posicionamento político e da análise de sentimentos e emoções. Para tanto, foi criado um modelo computacional com a finalidade de identificar câmaras de eco presentes em um corpus de tweets coletado entre os dias 8 e 10 de janeiro de 2023. Os dados obtidos demonstram uma nítida separação que reflete uma polarização significativa na rede social, com grupos distintos de usuários discutindo principalmente dentro de suas próprias bolhas ideológicas, evidenciando a existência de câmaras de eco. A análise dos tópicos extraídos das comunidades revela padrões distintos de conversação entre os grupos com diferentes polaridades políticas, sendo as discussões nessas comunidades centradas na defesa ou oposição aos atos e às ações do governo e das instituições que buscaram contê-los. Foi possível identificar, ainda, a prevalência de emoções como raiva e aborrecimento, já que a troca de acusações e a retórica inflamada contribuem para a expressão predominante de emoções negativas.
Palavras-chave: câmaras de eco; redes sociais; processamento de linguagem natural; comunidades políticas.
POLITICAL ECHO CHAMBERS DURING ANTI-DEMOCRATIC ACTS:
Twitter/X interaction topology
Abstract
The formation of echo chambers is a phenomenon in which users are often exposed to points of view that reinforce their beliefs, making it difficult to be exposed to divergent perspectives. While it is known about the emergence and dissemination of echo chambers that form in online communities, the automatic identification and understanding of this phenomenon emerges as an important tool to assist the investigation of its implications in the political sphere and democracy. The objective of this article is to investigate, implement and evaluate methods for the detection of echo chambers in digital social networks during the Anti-Democratic Acts of January 8, 2023. The investigation of this phenomenon was carried out through the combination of network-based community modeling, political positioning analysis, and sentiment and emotion analysis. To this end, a computer model was created in order to identify echo chambers present in a corpus of tweets collected between January 8 and 10, 2023. The data obtained demonstrate a clear separation that reflects a significant polarization in the social network, with distinct groups of users arguing mainly within their own ideological bubbles, evidencing the existence of echo chambers. The analysis of the topics extracted from the communities reveals distinct patterns of conversation between the groups with different political polarities, with the discussions in these communities centered on the defense or opposition to the acts and actions of the government and the institutions that sought to contain them. It was also possible to identify the prevalence of emotions such as anger and annoyance, since the exchange of accusations and inflammatory rhetoric contribute to the predominant expression of negative emotions.
Keywords: echo chambers; social networks; natural language processing; political communities.
CÁMARAS DE ECO POLÍTICAS DURANTE ACTOS ANTIDEMOCRÁTICOS:
Topología de interacción Twitter/X
Resumen
La formación de cámaras de eco es un fenómeno en el que los usuarios a menudo están expuestos a puntos de vista que refuerzan sus creencias, lo que dificulta estar expuestos a perspectivas divergentes. Si bien se sabe sobre el surgimiento y la difusión de las cámaras de eco que se forman en las comunidades en línea, la identificación y comprensión automática de este fenómeno surge como una herramienta importante para ayudar a la investigación de sus implicaciones en la esfera política y la democracia. El objetivo de este artículo es investigar, implementar y evaluar métodos para la detección de cámaras de eco en redes sociales digitales durante los Actos Antidemocráticos del 8 de enero de 2023. La investigación de este fenómeno se llevó a cabo a través de la combinación de modelos comunitarios basados en redes, análisis de posicionamiento político y análisis de sentimientos y emociones. Para ello, se creó un modelo informático con el fin de identificar las cámaras de eco presentes en un corpus de tuits recogidos entre el 8 y el 10 de enero de 2023. Los datos obtenidos demuestran una clara separación que refleja una importante polarización en la red social, con distintos grupos de usuarios discutiendo principalmente dentro de sus propias burbujas ideológicas, evidenciando la existencia de cámaras de eco. El análisis de los temas extraídos de las comunidades revela distintos patrones de conversación entre los grupos con diferentes polaridades políticas, con las discusiones en estas comunidades centradas en la defensa u oposición a los actos y acciones del gobierno y las instituciones que buscaban contenerlos. También fue posible identificar la prevalencia de emociones como la ira y la molestia, ya que el intercambio de acusaciones y la retórica incendiaria contribuyen a la expresión predominante de emociones negativas.
Palabras clave: cámaras de eco; redes sociales; procesamiento del lenguaje natural; comunidades políticas.
1 INTRODUÇÃO
As plataformas de mídia social desempenham um papel cada vez mais importante na esfera política, oferecendo acesso direto a uma quantidade sem precedentes de conteúdo. Essas plataformas permitem a disseminação de informações e desinformações (Vicario, 2016), a participação cívica e a formação de opiniões, tornando as redes sociais digitais ferramentas influentes na esfera política (Geiss; Sakketou; Flek; 2022).
As redes sociais digitais podem, ainda, contribuir para a formação de câmaras de eco (echo chambers), um fenômeno no qual os usuários são predominantemente expostos a pontos de vista que reforçam suas crenças existentes, dificultando a exposição a perspectivas divergentes.
De acordo com Garimella et al. (2018), uma câmara de eco no contexto político é definida como uma situação na qual a inclinação política do conteúdo que os usuários recebem de sua rede social concorda com a inclinação política do conteúdo que eles compartilham.
A Figura 1 ilustra os principais componentes de uma câmara de eco que, interligados, operam em um ciclo de feedback: algoritmos de recomendação (Recommender Algorithms) relacionados a sistemas automáticos, viés de confirmação (Confirmation Bias) e dissonância cognitiva (Cognitive Dissonance) ligados à psicologia humana, bem como a homofilia (Homophily) associada às redes sociais (Jiang et al., 2021). Embora esses componentes não dependam mutuamente, estão interconectados de forma que o ciclo reforce a presença mútua.
Os algoritmos de recomendação personalizam informações com base no histórico de comportamentos passados dos usuários, criando um universo de informações único para cada um (Cinelli et al., 2021). Por exemplo, quando se clica em um artigo de notícias, sinaliza-se o interesse no assunto do qual trata o artigo, levando os algoritmos a oferecerem mais conteúdo similar no futuro. Isso leva os usuários a receberem informações cada vez mais personalizadas, resultando em: (1) uma visão limitada do mundo, (2) desconhecimento sobre como as recomendações são feitas e (3) perda de controle sobre o processo (Pariser 2011).
O viés de confirmação é a tendência humana de buscar, interpretar, favorecer e lembrar informações que estejam de acordo com opiniões preexistentes (Nickerson, 1998). De acordo com a pesquisa sobre exposição seletiva (Frey, 1986), os humanos têm a tendência de buscar informações que confirmem suas crenças enquanto evitam informações que as desafiem.
Figura 1- Os componentes de uma câmara de eco
Fonte: Adaptado de Alatawi et al. (2021)
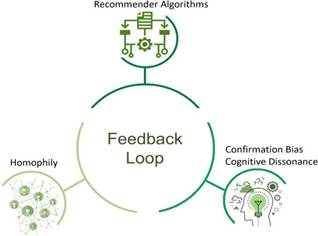 |
A dissonância cognitiva, por sua vez, refere-se a uma contradição interna entre duas opiniões, crenças ou conhecimentos (Festinger, 1957). À medida que as pessoas buscam por consistência, elas experimentam uma pressão psicológica para minimizar ou erradicar o desconforto gerado pela dissonância. Desse modo, Festinger (1957) introduziu três estratégias principais para redução da dissonância:
(1) a modificação de uma ou mais crenças, opiniões ou comportamentos;
(2) a busca por consistência por meio da aquisição de novas informações ou crenças; e
(3) a minimização ou o esquecimento da importância de certos conhecimentos.
As câmaras de eco são consideradas uma das práticas que podem ser utilizadas para reduzir a dissonância cognitiva. Segundo Evans e Fu (2018), as pessoas procuram por plataformas e interações ideologicamente coerentes para evitar o contato com indivíduos que confrontam suas ideias.
Por fim, a homofilia é o princípio de que pessoas com características similares tendem a se conectar com mais frequência entre elas do que com pessoas diferentes, seja devido a características intrínsecas (como sexo ou raça) ou valores compartilhados (McPherson; Smith-Lovin; Cook, 2001). Desse modo, as câmaras de eco têm o potencial de criar comunidades segmentadas, homogêneas e ideologicamente polarizadas.
O Twitter/X é um exemplo de site de rede social permeado por diversas publicações e com grande conteúdo voltado para discussões políticas, com uma base global de mais de 618 milhões de usuários ativos, incluindo 22 milhões no Brasil em 20241[5]. No Brasil, pesquisas sugerem que cerca de 60% dos usuários da plataforma compartilham informações encontradas na rede e que mais de 40% a consideram sua principal fonte de conteúdo político[6]. Portanto, com uma base tão expressiva de usuários no Brasil e em todo o mundo, o Twitter/X é propenso a abrigar câmaras de eco políticas, onde o compartilhamento seletivo de informações pode reforçar visões políticas específicas e ampliar a polarização.
Enquanto sabe-se do surgimento e da disseminação das câmaras de eco que se formam em comunidades online, a identificação automática deste fenômeno surge como uma importante ferramenta para auxiliar a investigação das suas implicações na esfera política e na democracia.
O objetivo deste artigo é a investigação, implementação e avaliação de métodos para a detecção de câmaras de eco em redes sociais digitais durante os Atos Golpistas de 8 de Janeiro de 2023, bem como a análise desse fenômeno por meio da combinação de modelagem de comunidades baseada em redes, da análise de posicionamento político e da análise de sentimentos e emoções.
Para tanto, foi criado um modelo computacional com a finalidade de identificar câmaras de eco presentes em um corpus de tweets publicados entre os dias 8 e 10 de janeiro de 2023.
As invasões das sedes dos Três Poderes em Brasília tiveram como intuito instigar um golpe militar no Brasil contra o governo eleito de Luiz Inácio Lula da Silva para restabelecer Jair Bolsonaro como presidente da nação. Os atos de vandalismo e depredações do patrimônio público foram cometidos por uma multidão de bolsonaristas extremistas, inconformados com o resultado eleitoral. Portanto, presumindo que possam ser identificadas comunidades atuando em perspectivas diametralmente opostas nas mídias sociais no que diz respeito aos atos, considera-se esse um período propício para a identificação e validação de câmaras de eco.
2 MATERIAIS E MÉTODOS
Nesta seção são descritos os materiais utilizados no desenvolvimento deste artigo (seção 2.1), bem como os principais métodos empregados nesta pesquisa (seção 2.2).
2.1 MATERIAIS
Os materiais disponíveis para viabilizar esta pesquisa foram: o conjunto de dados textuais (2.1.1), as hashtags usadas como ponto de partida para a classificação (2.1.2) e as ferramentas de análise textual (2.1.3).
2.1.1 CORPUS DA PESQUISA
O corpus desta pesquisa consistiu em 186.510 tweets que possuíam hashtags, publicados entre os dias 8 e 10 de janeiro de 2023. Esse corpus se trata de um subconjunto do dataset ITED-Br (Iasulaitis et al, 2024), coletado pelo Núcleo de Estudos Sociopolíticos dos Algoritmos e da Inteligência Artificial - Interfaces. O ITED-Br é composto por 282 milhões de tweets relacionados às eleições presidenciais de 2022, cuja coleta ocorreu a partir de 20/06/2022 e se estendeu até 31/01/2023 englobando, portanto, os eventos do dia 08/01/2023 (conhecidos como Atos Antidemocráticos) para os quais queries específicas de coleta também foram definidas. O corpus em questão contém mensagens curtas (tweets) publicadas no Twitter/X.
Esse subconjunto inicial totalizou 186.510 tweets que possuíam hashtags e, após a remoção dos tweets com classificações conflitantes, conforme descrito na Seção 2.2.1, 164.289 tweets foram classificados conforme apresentado na Figura 3.
2.1.2 LISTA DE HASHTAGS CLASSIFICADAS
Além do corpus, foi utilizado um conjunto de hashtags previamente classificadas pela equipe de cientistas políticos do Interfaces nas seguintes categorias: “pró-Bolsonaro”, “anti-Bolsonaro”, “pró- Lula”, “anti-Lula” e “neutro”. A partir dessas classificações, foi possível categorizar os tweets de acordo com a orientação política implícita nas hashtags utilizadas. O Quadro 1 traz exemplos de tweets e suas respectivas categorias.
|
Quadro 1- Exemplos de tweets rotulados para cada uma das categorias |
|
|
Tweet |
Categoria |
|
“O mundo inteiro está apoiando o presidente Lula.” Sim,o Brasil não é do mundo todo e sim de seus habitantes. #Foraladrão |
pró-Bolsonaro |
|
Medida do ministro do STF é referente a atos de terrorismo e vandalismo em Brasília. #JornalDaki #Bolsoterrorismo |
anti-Bolsonaro |
|
Sempre q tentam esnocar Lula, ele se sai magistralmente. #LulaGigante |
pró-Lula |
|
@renanbulba @Paulogeneroso Renan, Dilma, Lula e outros voltaram, eles são os verdadeiros Terroristas. Estude a história do Brasil, ……. #lulanazista #lulastalinista |
anti-Lula |
|
Lula decreta intervenção federal no GDF até 31 de janeiro de 2023 #Notícias #Política |
neutro |
|
Fonte: autoria própria. |
|
2.1.3 FERRAMENTAS
Para implementação, utilizou-se a linguagem de programação Python. e suas bibliotecas: Pandas (Team 2024), destinada à manipulação de base de dados (data frames); igraph (CCsardi; Nepusz 2006), destinada à criação, manipulação e análise de grafos; e CDlib (Rossetti; Milli; Cazabet 2019), destinada a algoritmos de detecção de comunidades.
Também foram utilizadas ferramentas para análise textual, como o GoEmotions[7] (Hammes; Freitas, 2021), para a detecção de emoções em textos, e o KeyBERT (Grootendorst 2020)[8], para extração de palavras-chave relevantes.
2.2 MÉTODOS
Nesta seção são detalhadas as estratégias de estruturação da topologia de rede e as abordagens de detecção de câmaras de eco implementadas nesta pesquisa. Para tanto, os métodos são apresentados na ordem das etapas realizadas, conforme ilustrado no fluxograma da Figura 2.
Figura 2 – Fluxograma das etapas da pesquisa
Fonte: autoria própria.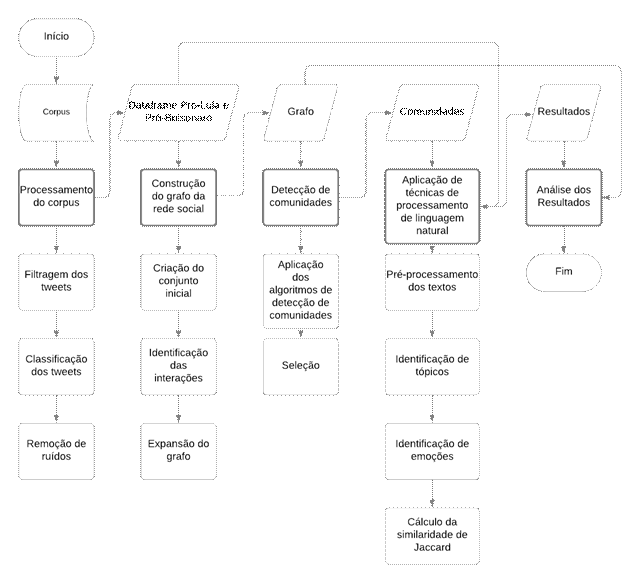
2.2.1 PROCESSAMENTO DO CORPUS
A partir das hashtags classificadas, foi possível categorizar automaticamente os tweets associando-os às respectivas orientações políticas. Durante esse processo, tweets com hashtags de polaridades conflitantes – tanto pró-Lula quanto pró-Bolsonaro – foram removidos da amostra para evitar ruído nos dados.
Desse modo, foi possível identificar os usuários correspondentes aos autores dos tweets feitos no período, os quais foram divididos em dois grupos: Pró-Bolsonaro ou Pró-Lula. Para a inclusão de um usuário em um desses grupos adotou-se o seguinte procedimento: um usuário era categorizado como Pró-Bolsonaro se seus tweets continham apenas hashtags Pró-Bolsonaro, Anti-Lula ou neutro, e como Pró-Lula se seus tweets apenas continham hashtags Pró-Lula, Anti-Bolsonaro ou neutro. Visando evitar ruído nos dados, os usuários cujos tweets apresentavam hashtags de ambas as classes foram excluídos da análise.
Embora este grupo representasse cerca de 10% do total de usuários, sua exclusão assegurou que cada usuário incluído na análise fosse inequivocamente identificado em uma única categoria.
2.2.2 CONSTRUÇÃO DO GRAFO DA REDE SOCIAL
Para a criação do grafo, inicialmente foram considerados os dois conjuntos (Pró-Bolsonaro e Pró-Lula) e, a partir do conjunto combinado dos usuários, foi realizada a construção da rede social representada por meio de um grafo não direcionado onde os vértices representam os usuários e as arestas entre dois usuários representam interações entre eles, como respostas, retweets ou menções.
Para a construção do grafo, iniciou-se com um subconjunto de usuários e foi utilizado um algoritmo semelhante ao Breadth First Search (BFS). Neste algoritmo, cada usuário é conectado a todas as pessoas com quem interagiu em, ao menos, um tweet, e essas novas pessoas são então verificadas para novas interações.
O processo foi realizado da seguinte maneira:
• Seleção do Subconjunto Inicial: foi escolhido um subconjunto de usuários aleatórios para iniciar a construção do grafo;
• Identificação de Interações: para cada tweet do subconjunto inicial, foram identificadas as menções, respostas, retweets e citações. Cada interação identificada gerou uma conexão (aresta) no grafo;
• Expansão do Grafo: a partir das conexões estabelecidas no passo anterior, foram identificados novos usuários a serem adicionados ao grafo. Foi repetido o processo de identificação de interações para esses novos usuários, expandindo o grafo iterativamente até que não houvesse novos usuários a serem adicionados.
Esse processo possibilita uma representação mais abrangente e significativa da rede social, assegurando uma exploração completa das interações entre os usuários na amostra de dados sob análise.
2.2.3 DETECÇÃO DE COMUNIDADES
Para identificar câmaras de eco, é essencial definir uma estratégia para particionar o grafo de interações em clusters homogêneos. Isso permite identificar grupos de indivíduos que interagem frequentemente entre si. Em redes complexas, a detecção de comunidades é uma abordagem popular para agrupar nós, ou seja, para criar os clusters. Porém, não existe uma definição única do que constitui uma comunidade, e diversos algoritmos foram propostos para particionar grafos eficientemente.
Para analisar qual dos algoritmos propostos na literatura seria o mais adequado para o contexto deste trabalho, experimentos foram realizados com quatro algoritmos: Louvain (Blondel et al., 2008), Leiden (Traag; Waltman; Eck, 2019), Infomap (Rosvall; Bergstrom, 2008) e Propagação de Rótulos (Cordasco; Gargano, 2011). Cada um desses algoritmos possui uma abordagem distinta para identificar comunidades:
• Louvain: este algoritmo é amplamente utilizado devido à sua eficiência e rapidez. O Louvain funciona em duas fases principais. Na primeira fase, cada nó começa em sua própria comunidade. Em seguida, o algoritmo itera sobre cada nó, movendo-o para a comunidade de seu vizinho que proporciona o maior aumento na modularidade, que é uma medida da densidade de ligações dentro das comunidades comparada à densidade de ligações entre comunidades. Na segunda fase, as comunidades formadas na primeira fase são agregadas em novos nós e o processo se repete. Isso cria uma hierarquia de comunidades, maximizando a modularidade.
• Leiden: este algoritmo é uma melhoria do método de Louvain, assegurando uma maior qualidade das comunidades detectadas e evitando a formação de comunidades desconexas. Ele otimiza a modularidade de forma mais eficiente, dividindo e refinando comunidades iterativamente até que nenhuma melhoria adicional possa ser alcançada. O Leiden é conhecido por sua capacidade de gerar comunidades mais bem conectadas internamente.
• Infomap: o Infomap é baseado na minimização do comprimento da descrição de um passeio aleatório pela rede. Diferentemente de outros algoritmos que utilizam a modularidade como função objetivo, o Infomap usa a equação do mapa (map equation). Esta equação explora a dualidade entre encontrar estruturas de cluster na rede e minimizar o comprimento da descrição do movimento de um passeio aleatório (random walk). O algoritmo busca formar clusters nos quais o caminhante aleatório permaneça o maior tempo possível.
• Propagação de Rótulos: Um algoritmo simples e rápido que atribui rótulos aos nós da rede e os propaga através das conexões até que um estado estável seja alcançado. Cada nó adota o rótulo que é mais comum entre seus vizinhos, resultando em comunidades onde os nós compartilham o mesmo rótulo. A principal vantagem desse método é sua simplicidade e eficiência computacional, tornando-o adequado para grandes redes.
Implementar esses algoritmos permitiu identificar e analisar as diferentes comunidades formadas na rede social, proporcionando uma compreensão mais profunda das dinâmicas de interação entre os usuários. A avaliação da qualidade das comunidades geradas por esses algoritmos foi realizada utilizando diversas métricas que ajudaram a entender melhor a eficácia de cada algoritmo:
● Modularidade: Mede a qualidade da divisão da rede em comunidades, comparando a densidade de arestas dentro das comunidades com a densidade de arestas entre comunidades. Valores mais altos indicam uma melhor divisão, sugerindo que as comunidades são mais densamente conectadas internamente do que externamente.
![]()
onde m é o número de arestas no grafo, S é uma comunidade, mS é o número de arestas na comunidade e lS é o número de arestas dos vértices em S para os vértices fora de S.
• Expansão: Relação de arestas por vértices que possuem conexões fora da comunidade. Valores menores indicam uma melhor separação entre comunidades, significando que há poucas conexões entre as diferentes comunidades.
![]()
onde cS é o conjunto de arestas que possuem conexões para fora da comunidade e nS é o número de vértices da comunidade.
• Condutância: Relação do total do volume de todas as arestas que apontam para fora da comunidade. Valores menores representam uma separação mais clara.
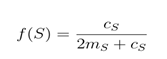
onde cS é o número de vértices da comunidade e mS é o número de arestas da comunidade.
• Dominância de hubs: A dominância de hubs de uma comunidade é definida como a razão entre o grau do nó mais conectado da comunidade e o grau máximo teoricamente possível dentro dessa comunidade. Em outras palavras, mede o grau de influência dos nós mais conectados na estrutura da comunidade. Um valor mais alto indica que um ou mais hubs têm uma presença dominante na comunidade.
• Número de Comunidades: Indica a quantidade de comunidades detectadas pelo algoritmo, o que contribui para entender o nível de granularidade na divisão da rede.
Assim, após a experimentação com os algoritmos citados e o cálculo das medidas apresentadas, o melhor algoritmo foi selecionado buscando-se atender aos seguintes critérios: alta modularidade, baixa expansão, baixa condutância, alta dominância de hubs e um número razoável (nem muito grande, nem muito pequeno) de comunidades.
2.2.4 PROCESSAMENTO DE LINGUAGEM NATURAL
Após a detecção das comunidades, procedeu-se com a aplicação de técnicas de PLN com o intuito de agregar valor linguístico à análise dos tweets presentes nas comunidades. Esse procedimento iniciou-se com uma etapa de pré-processamento para limpeza e normalização, que envolveu a eliminação de caracteres especiais, links, hashtags e menções – que não agregam informação diretamente ao conteúdo dos textos e poderiam afetar a análise – assim como a mudança para minúsculas, remoção de stopwords – palavras comuns, como artigos, preposições e conjunções e outros ruídos – e outros ruídos como quebras de linha, vogais, pontuações e espaços extras. Essa é uma etapa importante para assegurar que apenas informações pertinentes à análise sejam preservadas. Além disso, identificou-se que uma parte significativa dos dados consistia em retweets, o que poderia potencialmente enviesar a percepção dos tópicos discutidos e das emoções expressas nos documentos, portanto optou-se por realizar experimentos tanto considerando dados contendo os retweets quanto sem esses retweets.
Para a extração de tópicos e identificação de padrões dentro dos tweets, foi utilizada a biblioteca KeyBERT com o modelo xlm-r-distilroberta-base-paraphrase-v1 (Reimers; Gurevych 2019), um sentence transformer projetado para capturar semelhanças semânticas entre textos. Este modelo não apenas facilita a detecção de paráfrases, mas também contribui na categorização precisa dos temas discutidos nos tweets.
Para uma análise mais profunda das interações emocionais dentro das comunidades, foi aplicado o modelo GoEmotions em português. Este modelo é capaz de identificar 27 emoções distintas em textos como admiração, raiva e curiosidade. A análise das emoções predominantes proporcionou insights valiosos sobre o clima emocional e as motivações subjacentes aos discursos nas comunidades estudadas.
Adicionalmente, foi calculada a média da similaridade de Jaccard entre os usuários dentro de cada comunidade. Essa medida estatística compara a sobreposição de conjuntos de palavras nos tweets de cada usuário, refletindo a proximidade de interesses e opiniões expressos textualmente pelos membros da mesma comunidade. A fórmula da similaridade de Jaccard é dada por:
![]()
onde A e B são os conjuntos de palavras dos tweets de dois usuários. A alta similaridade de Jaccard entre os pares de usuários reforça a hipótese de existência de câmaras de eco, onde há uma convergência significativa de conteúdos discutidos e perspectivas compartilhadas.
3 RESULTADOS E DISCUSSÃO
Foram analisados tweets publicados entre os dias 8 e 10 de janeiro de 2023, período marcado pelos Atos Antidemocráticos ocorridos no Brasil. Esse subconjunto inicial totalizou 186.510 tweets que possuíam hashtags e, após a remoção dos tweets com classificações conflitantes, conforme descrito na Seção 2.2.1, 164.289 tweets foram classificados conforme apresentado na Figura 3.
Figura 3 – Distribuição dos tweets de acordo com sua classificação
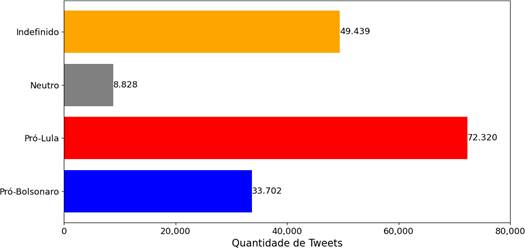 |
A distribuição dos tweets entre as diferentes categorias revela uma predominância significativa de tweets pró-Lula (44,02%) em comparação com tweets pró-Bolsonaro (20,51%). Essa predominância pode ser atribuída aos eventos ocorridos no dia 8 de janeiro de 2023, onde houve uma reação intensa e generalizada contra os atos antidemocráticos. Esse contexto provavelmente levou a um aumento nas menções positivas ao candidato (e recém eleito presidente) Lula, visto como um representante da oposição aos atos.
Além disso, um número considerável (30,09%) de tweets (49.439) foi classificado como “Indefinido”. Essa categoria inclui muitos tweets que mencionavam outros atores políticos, ou abordavam temas que não estavam diretamente relacionados aos candidatos Bolsonaro e Lula.
Com base nos tweets classificados, foi possível classificar os usuários com uma polaridade política, conforme resumido na Tabela 1.
Quadro 1 – Usuários Classificados
|
Quantidade de usuários |
|
|
pró-Bolsonaro |
16.197 |
|
pró-Lula |
37.465 |
|
TOTAL |
53.662 |
Fonte: autoria própria
Seguindo o procedimento descrito na Seção 2.2.2, foi criado o grafo utilizando-se 50.000 tweets como sementes, que foi expandido usando-se o algoritmo Breadth First Search (BFS). Ao final desse processo, o grafo gerado possui 36.384 vértices e 50.623 arestas. É importante destacar que o número total de vértices não é igual ao total de usuários, pois a expansão do grafo, a partir dos tweets sementes, fez com que ele se expandisse de forma seletiva. Como resultado, alguns usuários que não estavam inicialmente no conjunto de tweets sementes, ou que não foram referenciados em nenhum tweet, não foram incluídos no grafo final. A Figura 4 ilustra o grafo obtido, com 36.384 vértices e 50.623 arestas, sendo que os vértices azuis são os usuários que possuem polaridade pró-Bolsonaro, os vértices vermelhos são os usuários que possuem polaridade pró-Lula e os vértices cinzas são os que não foram classificados.
Figura 4 – Grafo da rede social pró-Lula e pró-Bolsonaro
Fonte: autoria própria
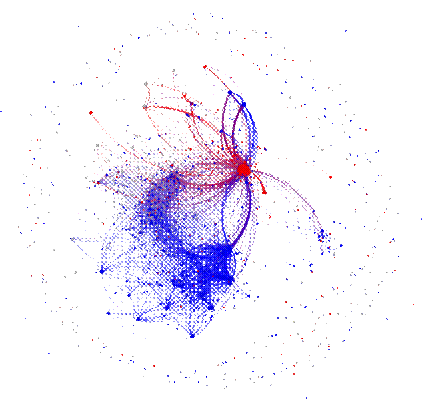 |
Para identificar câmaras de eco dentro da rede, foram comparados os algoritmos de detecção de comunidades utilizando as métricas mencionadas na seção 2.2.3. A Tabela 2 apresenta os resultados obtidos para essas métricas, com destaque (em negrito) para os melhores valores em cada uma. Após a análise dos valores gerados para as métricas para a saída de cada algoritmo, optou-se por utilizar o algoritmo Leiden. Embora ele tenha tido um desempenho inferior em algumas métricas em comparação com os outros algoritmos, como o Louvain ou o Infomap, o Leiden ainda obteve bons resultados e, conforme mencionado em Traag, Waltman e Eck (2019), ele evita a formação de comunidades desconexas, um problema que pode ocorrer com o algoritmo Louvain. A robustez do Leiden em manter comunidades bem conectadas internamente e a sua capacidade de evitar comunidades desconexas foram fatores decisivos para sua seleção, mesmo com um desempenho inferior em algumas métricas quando comparado ao Infomap.
Tabela 2 – Comparação dos algoritmos de detecção de comunidades
|
Modularidade |
Condutância |
Expansão |
Dominância Hubs |
Nº Comunidades |
|
|
Louvain |
0.626072 |
0.046764 |
0.086485 |
0.964169 |
440 |
|
Leiden |
0.633907 |
0.052511 |
0.099089 |
0.969614 |
493 |
|
Infomap |
0.504197 |
0.004210 |
0.011506 |
0.980082 |
362 |
|
Propagação de Rótulos |
0.544466 |
0.382420 |
1.239888 |
0.982072 |
1869 |
Fonte: autoria própria
Analisando o tamanho das comunidades detectadas pelo algoritmo Leiden, notou-se que algumas comunidades são significativamente maiores que outras. Devido ao pequeno tamanho de muitas das comunidades detectadas, decidiu-se focar a análise nas 10 maiores comunidades, ou seja, as top-10 comunidades em termos de quantidade de usuários envolvidos. Essa decisão visou garantir que as análises subsequentes (emoções, tópicos e similaridade de Jaccard) fossem baseadas em dados robustos e representativos.
Os resultados da detecção de comunidades pelo algoritmo Leiden, para as top-10 comunidades, são apresentados na Figura 5. A figura mostra a porcentagem de usuários pró-Bolsonaro, pró-Lula e Indefinido em cada comunidade, bem como o tamanho de cada comunidade. Apesar de terem sido utilizados dados filtrados para incluir apenas indivíduos pró-Lula e pró-Bolsonaro, algumas comunidades apresentam uma categoria de usuários classificados como “indefinidos”. Esses indefinidos surgem porque, embora os usuários pertencentes à comunidade sejam principalmente pró-Lula ou pró-Bolsonaro, eles também podem ter mencionado atores políticos fora desses espectros específicos, resultando na inclusão de usuários não classificados por hashtags nas análises.
Figura 5 – Top-10 comunidades classificadas, em termos que quantidade de usuários, pelo algoritmo Leiden.
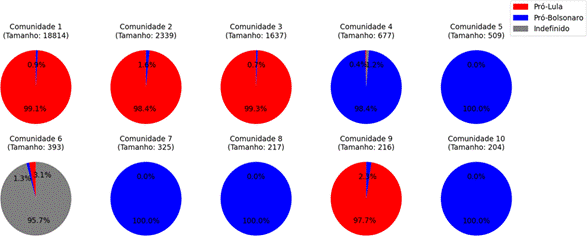
Fonte: autoria própria
A Figura 5 mostra uma clara separação política nas comunidades detectadas pelo algoritmo Leiden. A maioria das comunidades é composta predominantemente por usuários pró-Lula ou pró-Bolsonaro, reforçando a ideia da existência de câmaras de eco onde os usuários interagem principalmente com outros que compartilham a mesma orientação política. Essa separação reflete uma polarização significativa na rede social, com grupos distintos de usuários discutindo principalmente dentro de suas próprias bolhas ideológicas.
Além disso, foram calculadas as métricas de condutância, expansão e dominância de hubs para essas top-10 comunidades, conforme apresentado na Tabela 3. A interpretação dessas métricas foi detalhada na Seção 2.2.3. Essas métricas fornecem uma avaliação quantitativa da qualidade das comunidades detectadas.
Tabela 3 – Valores para as métricas de avaliação nas top-10 comunidades
|
Condutância |
Expansão |
Dominância de Hubs |
|
|
1 |
0,108 |
0,242 |
0,999 |
|
2 |
0,385 |
1,255 |
0,996 |
|
3 |
0,234 |
0,611 |
1,000 |
|
4 |
0,267 |
1,715 |
0,485 |
|
5 |
0,238 |
0,625 |
0,998 |
|
6 |
0,140 |
0,326 |
1,000 |
|
7 |
0,278 |
0,766 |
1,000 |
|
8 |
0,553 |
2,631 |
0,926 |
|
9 |
0,131 |
0,588 |
0,986 |
|
10 |
0,464 |
1,730 |
0,985 |
Fonte: autoria própria
Comunidades com baixa condutância e alta dominância de hubs tendem a ser mais isoladas, com uma estrutura que favorece a centralização de informações em torno de poucos indivíduos influentes. Isso pode indicar a presença de câmaras de eco, onde as ideias e opiniões são reforçadas internamente com pouca influência externa. Nesse sentido, nota-se que as comunidades pró-Bolsonaro (em azul na Tabela 3) apresentam condutância entre 0,238 e 0,553 enquanto as comunidades pró-Lula (em vermelho), apresentam um intervalo de condutância entre 0,108 e 0,385. Em relação à dominância de hubs, não é possível notar nenhuma diferença nas comunidades desses dois grupos, uma vez que apenas uma, a comunidade 4 (pró-Bolsonaro), apresenta valor muito diferente dos demais (0,485).
A métrica de expansão, por sua vez, reflete a conectividade das comunidades com outras partes da rede. Comunidades com baixa expansão são mais fechadas, o que pode contribui para o comportamento típico das câmaras de eco. Já as comunidades com maior expansão têm uma maior probabilidade de interagir com outros grupos, o que pode reduzir o isolamento e a polarização. Em relação a essa métrica, as comunidades pró-Lula apresentaram uma expansão média de 0,674 e só a comunidade 2 extrapolou este valor. A média de expansão para as comunidades pró-Bolsonaro foi maior (1,493) e três das cinco comunidades extrapolaram este valor: 4, 8 e a 10.
3.1 ANÁLISE DE TÓPICOS DAS COMUNIDADES
Após a detecção das comunidades, para amparar a análise de possíveis câmaras de eco dentro delas, realizou-se a análise de tópicos com base em palavras-chave. O processo de identificação de palavras-chave foi realizado para identificar os tópicos principais de cada comunidade. As Tabelas 4 e 5 listam os tópicos mais relevantes para cada uma das top-10 comunidades considerando e sem considerar os retweets, respectivamente. Novamente, as comunidades pró-Lula são identificadas em vermelho, enquanto as comunidades pró-Bolsonaro são indicadas em azul.
Tabela 4 – Principais tópicos das top-10 comunidades considerando retweets
Comunidade Com Retweets
1 dificuldades, problema, brasileiras, brasileñas, resolver
2 brasileiras, brasileira, brasileiros, brasileiro, brasil
3 patriotários, brasileira, quemtemfometempressa, valerão, providências
4 ditaduras, culturais, ditadores, brasileiros, humilhação
5 impeachment, patriotários, extradição, patriota, terrorista
6 incomoda, várias, verdadeiramente, fazemos, companheiros
7 impeachment, infiltrados, delegacia, patriotários, mp
8 brasileiras, brasil, brasileiro, brasileiros
9 patriotários, terroristas, bolsonaristas, bolsonarismo, ideológica
10 brasilia, fraudadas, brasil, brasileiros, fraudou
Fonte: autoria própria
Tabela 5 – Principais tópicos das top-10 comunidades desconsiderando retweets
Comunidade Sem Retweets
1 brasileiras, dificuldades, moraes, assistindo, brasileñas
2 depredaram, pessoal, desgraçado, patriotários, mp
3 quemtemfometempressa, brasileira, insurreição, contínuos, excluídos
4 ditaduras, culturais, ditadores, brasileiros, hipócritas
5 patriotas, patriota, infiltrados, golpistas, bolsonaristas
6 incomoda, várias, verdadeiramente, fazemos, companheiros
7 delegacia, 2023, impeachment, infiltrados, arrocha
8 favorecendo, nojentos, destruindo, fraudadas, golpistas
9 anti, ideológica, denunciar, terroristas, bozó
10 várias, fraudadas, apoiando, prisões, desprezo
Fonte: autoria própria
A análise dos tópicos extraídos das comunidades revela padrões distintos de conversação entre os grupos com diferentes polaridades políticas, especialmente no contexto dos eventos ocorridos no dia 8 de janeiro de 2023.
As comunidades predominantemente pró-Lula, como a Comunidade 1, 2 e 3, destacam-se pela frequência de termos relacionados a problemas sociais e nacionais. Palavras como “dificuldades”, “problema”, “resolver”, “brasileiras” e “brasileiros” são recorrentes. A presença de termos como “moraes” também sugere discussões sobre figuras jurídicas e políticas importantes, provavelmente relacionadas às decisões judiciais e ao papel do Judiciário durante os atos antidemocráticos.
Por outro lado, as comunidades majoritariamente pró-Bolsonaro, como as Comunidades 4, 5, 7, 8 e 10, têm uma forte ênfase em temas como “ditaduras”, “impeachment”, “patriotários”, “terroristas”, “fraudadas” e “golpistas”. Estes tópicos sugerem uma forte retórica de oposição e contestação. As discussões nessas comunidades parecem centradas na defesa dos atos e na oposição às ações do governo e das instituições que buscaram conter os atos antidemocráticos.
A análise dos tópicos com e sem retweets mostra que, em ambas as formas de comunicação, as preocupações e temas centrais permanecem consistentes. No entanto, a presença de retweets tende a amplificar certas discussões e palavras-chave, reforçando as mensagens centrais de cada grupo. Retweets ajudam a disseminar rapidamente informações e opiniões, fortalecendo as câmaras de eco dentro de cada comunidade.
Essas observações levantam algumas questões importantes para discussão:
• A comparação entre comunidades com e sem retweets pode revelar como a presença de retweets amplifica determinados tópicos ou termos e contribui para a formação de câmaras de eco, em comparação com as discussões que ocorrem sem retweets.
• Além disso, a repetição de tópicos e a presença de termos polarizados podem indicar a existência de câmaras de eco, onde há pouca diversidade de opinião e um reforço contínuo das mesmas narrativas.
3.2 ANÁLISE DE EMOÇÕES NAS COMUNIDADES
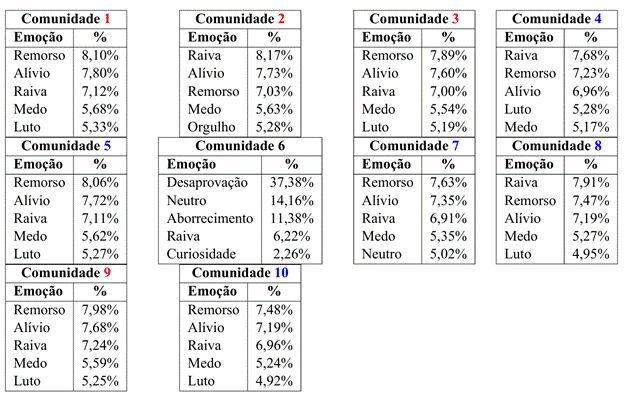
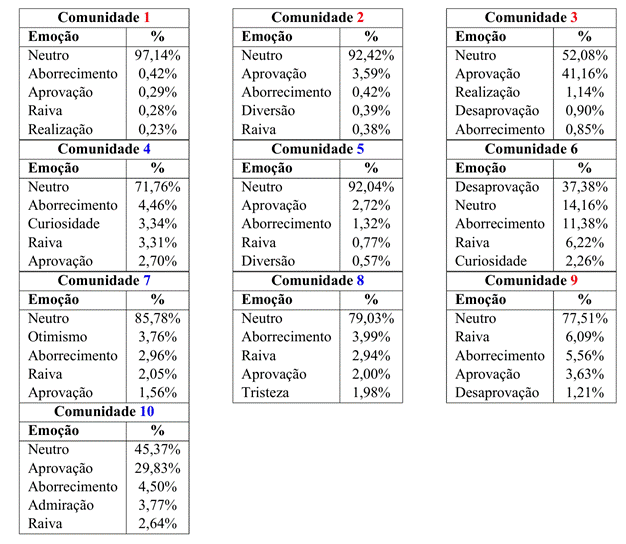
Para cada uma das top-10 comunidades, também foram analisadas as emoções mais frequentes com base na classificação automática realizada pelo GoEmotions, considerando a ausência (Tabela 6) e a presença (Tabela 7) de retweets.
A análise das distribuições emocionais nas diferentes comunidades, considerando as variações com e sem retweets, revela que desconsiderar retweets (valores da Tabela 6) pode ser uma estratégia interessante para identificar a verdadeira carga emocional, uma vez que quando os retweets são considerados a emoção predominante é o Neutro. Sem considerar os retweets, percebe-se que a distribuição de emoções é bem mais balanceada. Entretanto, as emoções negativas, como raiva e aborrecimento, têm uma presença mais marcante. Esses altos níveis de emoções negativas podem ser atribuídos ao clima político tenso e à polarização acentuada em torno dos eventos de 8 de janeiro. A troca de acusações e a retórica inflamada contribuem para a expressão predominante de emoções negativas. Em contraste, emoções positivas como alegria, amor e gratidão aparecem com menor frequência.
Tabela 6 – Top-5 emoções identificadas nas top-10 comunidades (sem retweet)
Fonte: autoria própria
É interessante notar que a única comunidade que destoa em termos das top-5 emoções identificadas é a Comunidade 6, considerada neutra, para a qual se identificou a presença de Desaprovação e Aborrecimento, emoções não identificadas entre as top-5 para as demais comunidades. Outro ponto a ser comentado sobre essa comunidade é que os valores das Tabelas 6 e 7 para ela são iguais porque esta comunidade não possui retweets. A Comunidade 6 contém 85 tweets e nenhum retweet.
Os dados revelam que há uma variação considerável nas distribuições emocionais das comunidades, com diferenças perceptíveis entre as interações com e sem retweets. Comunidades sem retweets apresentam uma diversidade maior de emoções, incluindo uma proporção significativa de emoções negativas, como raiva e remorso, refletindo o tom das discussões diretas entre os usuários. Já nas comunidades com retweets, observa-se uma presença expressiva de emoções neutras, o que pode indicar um padrão diferente de compartilhamento, possivelmente relacionado ao tipo de conteúdo que é mais frequentemente retweetado. Esses resultados destacam como diferentes formas de interação podem moldar as expressões emocionais nas comunidades estudadas, sugerindo que o contexto de cada interação desempenha um papel importante na dinâmica emocional observada.
Tabela 7 – Top-5 emoções identificadas nas top-10 comunidades (com retweet)
 Fonte: autoria própria
Fonte: autoria própria
3.3 SIMILARIDADE DE JACCARD NAS COMUNIDADES
Por fim, para verificar se as pessoas dentro das comunidades estão discutindo assuntos semelhantes, foi calculada a similaridade de Jaccard entre os conjuntos de palavras de cada usuário com todos os outros usuários dentro da mesma comunidade. Os resultados são apresentados na Tabela 8.
Tabela 8 – Média de Similaridade de Jaccard nas Comunidades
|
Com retweets |
Sem retweets |
|
|
1 |
97,44% |
4,92% |
|
2 |
73,83% |
5,56% |
|
3 |
72,05% |
4,79% |
|
4 |
18,03% |
4,58% |
|
5 |
79,28% |
3,70% |
|
6 |
11,05% |
11,05% |
|
7 |
33,51% |
3,10% |
|
8 |
43,34% |
4,30% |
|
9 |
67,47% |
10,16% |
|
10 |
73,21% |
3,66% |
Fonte: autoria própria
Os resultados indicam que a similaridade de Jaccard varia significativamente entre as comunidades. A Comunidade 1, considerando os retweets, apresenta uma similaridade extremamente alta, sugerindo que os usuários estão compartilhando e discutindo os mesmos assuntos de maneira quase homogênea. Contudo, vale destacar que esta comunidade possui 37.691 tweets dos quais 37.307 (98,98%) são retweets, ou seja, quase a totalidade da comunidade é de replicação de postagens e não de postagens novas.
Em contraste, as comunidades sem retweets geralmente apresentam uma similaridade de Jaccard muito menor. Esses resultados indicam que a diferença de similaridade de Jaccard entre as comunidades com e sem retweets é um fator crucial para identificar possíveis câmaras de eco. Em particular, as Comunidades 1, 2 e 5 exibem uma diferença significativa, com valores de similaridade muito mais altos na presença de retweets.
Essa grande disparidade sugere que os retweets estão reforçando os tópicos discutidos dentro dessas comunidades, contribuindo para a formação de câmaras de eco, onde o conteúdo é amplamente repetido e validado pelos membros. Nesses ambientes, o compartilhamento de informações parece homogeneizar as discussões, enquanto a ausência de retweets permite uma maior diversidade de tópicos e opiniões.
A Tabela 9 apresenta exemplos de tweets de duas comunidades distintas (uma pró-Lula e outra pró-Bolsonaro) e as emoções detectadas em cada um deles. É importante observar que existem classificações imprecisas, devido às limitações do modelo de identificação automática de emoções (GoEmotions), que tende a ter dificuldades em textos contendo sarcasmo e ironia.
Tabela 9 – Exemplos de tweets de três comunidades (uma pró-Lula, outra pró-Bolsonaro e uma indefinida) acompanhados da emoção identificada para eles
|
Tweet |
Emoção |
||
|
1 (pró-Lula) |
A frase “o mercado não reagiu bem” pode ser traduzida como “os ricos estão putos da vida porque Lula quer ajudar os pobres a comer 3 vezes ao dia”. É o capitalismo, estúpido! #LulaPresidenteDoBrasil #LulaEoBrasilSubindoARampa #Lula- Presidente |
Aborrecimento |
|
|
@DrBrunoGino BOLSONARO É CULPADO #BolsonaroNaCa-deia2023 |
Remorso |
|
|
|
Eu fiz o L Eu faço o L Eu farei o L Chupa meu L Engula meu L Durma com meu L Meu L é a certeza que estou do lado certo da história. #Lula #DemocraciaSempre |
Aprovação |
|
|
|
Comunicado conjunto Lula e Biden sobre a conversa de hoje. #EquipeLula https://t.co/jo9pht7jiY |
Neutro |
|
|
|
RT @PaulaGoBas: Lula conduzindo os governadores p q vejam os destroços q os bolsonaristas deixaram #LulaPresidente |
Neutro |
|
|
|
4 (pró-Bolsonaro) |
Arriscaram palmas depois da leitura do decreto da intervenção por Lula. Perceberam que não era o caso #oglobo |
Realização |
|
|
RT @Anneliz21271025: Olhe a Diferença das posses presidenciais no Brasil, e aí qual você acha melhor ..? #lulaladrao #SupremoEo- Povo #Bra… |
Curiosidade |
|
|
|
Ao vivo agora em Brasília! https://t.co/Xl2vMrz851 Mais alguém tem Links ao vivo? #GloboLixo https://t.co/BYqfqADLXz |
Curiosidade |
|
|
|
Esse pessoal sabe alguma coisa de direito internacional? Não mesmo. Não há crime, não há processo, querem imputar delitos a ele por atribuições, simples. Bolsonaro não será extraditado. Essa galera é burra pra caralho. #LulaVergonhaNacional #Bolsonaro- OrgulhoDoBrasil https://t.co/6d2CZeOAiy |
Aborrecimento |
|
|
|
RT @Jvzpereira94: #LULAGENOCIDA Típica hipocrisia da es- querda. Durante 4 anos chamaram a direita de fascistas, e agora gritam sem anisti… |
Aborrecimento |
|
|
|
6 (Indefinido) |
Lista SDV alternativa #EsquerdaSegueEsquerda @Guilasarmentorj ... @Nilsonhandebol |
Neutro |
|
|
@valfachi @PrjorgeS @pinho_ray @fafer16 @CHATO393458072 @silene_sousa13 @EspectroZC @Correia1089 @ANACARO38480043 @LoureiroMeire @silviootoni “Ain, não gosto da Globo” Não assista! “Ain, não gosto de Carnaval” Não vá! “Ain, não gosto do Bolsonaro” Me segue, que te SDV#LulaPresidente13 |
Desaprovação |
|
|
|
“Um Lulinha incomoda muita gente, uma Dilminha incomoda muito mais.” #LulaPresidenteDoBrasil https://t.co/8GncKoVFrv |
Aborrecimento |
|
|
|
Atenção: Após várias horas, segue a manifestação do ex-presidente Jair Bolsonaro. Alguns trechos citados, não batem com os fatos o que verdadeiramente ocorreu. #terrorismo #bolsora- ristas #INVASAODOCONGRESSO https://t.co/dWYp3yF2AP https://t.co/bKvKqfEhsR |
Neutro |
|
|
|
#lulapresidente13 @jacquel56731914 ... @ceara59 |
Neutro |
|
|
Fonte: autoria própria
Vale ressaltar que em alguns exemplos da Tabela 9 há tweets com hashtags com polaridade política pró-Lula ou pró-Bolsonaro que foram inseridos em comunidades classificadas de modo diferente dessa polaridade. Isso ocorre devido à metodologia adotada para gerar as comunidades que leva em consideração a totalidade de tweets e as menções a outros usuários.
4 CONCLUSÕES
Este estudo investigou a possibilidade de usar algoritmos de identificação de comunidades em redes sociais e técnicas de PLN para identificar câmaras de eco políticas em redes sociais. Para isso, considerou-se uma amostra de tweets postados durante um período de intensa atividade política no Brasil, especificamente entre os dias 8 e 10 de janeiro de 2023, durante os denominados Atos Antidemocráticos.
Os resultados indicam que as comunidades encontradas estavam bem definidas em relação à polaridade política, apresentando uma característica de câmaras de eco. Da análise de tópicos, conclui-se que cada grupo se concentra em narrativas que reforçam suas visões políticas específicas, com pouca diversidade temática. Essa consistência temática, independentemente da presença de retweets, sugere que a comunicação interna dentro de cada grupo serve para fortalecer e disseminar suas mensagens centrais, ampliando a polarização e limitando a exposição a opiniões divergentes.
Embora a análise de emoções tenha mostrado um padrão semelhante de ênfase em emoções negativas, a interpretação dos sentimentos nas comunidades ainda necessita de refinamento, uma vez que os dados obtidos não permitiram uma análise precisa sobre cada comunidade. Notou-se, também, que o modelo usado para identificar automaticamente as emoções (GoEmotions) apresentou erros que podem ser consequência de não ter sido treinado no gênero (Twitter) e domínio (política) usado neste trabalho.
Essas considerações evidenciam a necessidade de aprofundar a pesquisa sobre os mecanismos de formação e detecção de câmaras de eco. A complexidade do fenômeno requer abordagens multidimensionais, que considerem não apenas a estrutura da rede, mas também a polaridade, a dinâmica das opiniões, dos conteúdos compartilhados e possivelmente a análise de mais fatores.
Além disso, é crucial reconhecer que este estudo não explorou todos os fatores que podem influenciar a formação e a dissipação das câmaras de eco. Aspectos como a possibilidade de que essas câmaras possam se dissipar ao longo do tempo, ou a influência de fatores cognitivos que moldam o comportamento dos usuários, representam áreas promissoras para investigações futuras. A inclusão desses elementos em análises subsequentes pode oferecer uma compreensão ainda mais abrangente das dinâmicas das câmaras de eco.
Em síntese, este estudo contribui para revelar a complexidade das interações nas redes sociais, onde a polarização e a propagação de informações são mediadas tanto pela estrutura da rede quanto pelo comportamento dos usuários. A análise combinada de tópicos, emoções e similaridade de conteúdo fornece uma visão mais completa sobre como estão configuradas as câmaras de eco. Esses resultados podem direcionar futuras pesquisas para o desenvolvimento de métodos mais precisos de detecção e compreensão das dinâmicas dessas comunidades online.
AGRADECIMENTO
À FAPESP e ao CNPq, pelo financiamento desta pesquisa.
REFERÊNCIAS
ALATAWI, F. et al. A Survey on Echo Chambers on Social Media: Description, Detection and Mitigation. 2021.
BLONDEL, V. D. et al. Fast unfolding of communities in large networks. Journal of Statistical Mechanics: Theory and Experiment, IOP Publishing, v. 2008, n. 10, p. P10008, out. 2008. ISSN 1742-5468. Disponível em: <http://dx.doi.org/10.1088/1742-5468/2008/10/P10008>. Acesso em: 06 fev. 2025.
CINELLI, M. et al. The echo chamber effect on social media. Proceedings of the National Academy of Sciences, v. 118, n. 9, p. e2023301118, 2021. Disponível em: <https://www.pnas.org/doi/abs/10.1073/pnas.2023301118>. Acesso em: 05 fev. 2025.
CORDASCO, G.; GARGANO, L. Community detection via semi- synchronous label propagation algorithms. CoRR, abs/1103.4550, 2011. Disponível em: <http://arxiv.org/abs/1103.4550>. Acesso em: 05 fev. 2025.
CSARDI, G.; NEPUSZ, T. The igraph software package for complex network research. InterJournal, Complex Systems, p. 1695, 2006. Disponível em: <https://igraph.org>. Acesso em: 05 fev. 2025
EVANS, T.; FU, F. Opinion formation on dynamic networks: identifying conditions for the emergence of partisan echo chambers. Royal Society Open Science, v. 5, n. 10, p. 181122, 2018. Disponível em: <https://royalsocietypublishing.org/doi/abs/10.1098/rsos.181122>. Acesso em: 05 de fev. 2025
FESTINGER, L. A Theory of Cognitive Dissonance. Redwood City: Stanford Univer- sity Press, 1957. ISBN 9781503620766. Disponível em: <https://doi.org/10.1515/9781503620766>. Acesso em: 04 fev. 2025.
FREY, D. Recent research on selective exposure to information. In: BERKOWITZ, L. (Ed.). Academic Press, 1986, (Advances in Experimental Social Psychology, v. 19). p. 41–80. Disponível em: <https://www.sciencedirect.com/science/article/pii/S0065260108602129>. Acesso em: 06 fev. 2025.
GARIMELLA, K. et al. Political discourse on social media: Echo chambers, gatekeepers, and the price of bipartisanship. In: Proceedings of the 2018 World Wide Web Conference. Republic and Canton of Geneva, CHE: International World Wide Web Conferen- ces Steering Committee, 2018. (WWW ’18), p. 913–922. ISBN 9781450356398. Disponível em: <https://doi.org/10.1145/3178876.3186139>. Acesso em: 06 fev. 2025.
GEISS, H.-J.; SAKKETOU, F.; FLEK, L. OK boomer: Probing the socio-demographic divide in echo chambers. In: Proceedings of the Tenth International Workshop on Natural Language Processing for Social Media. Seattle, Washington: Association for Computational Linguistics, 2022. p. 83–105. Disponível em: <https://aclanthology.org/2022.socialnlp-1.8>. Acesso em: 04 fev. 2025.
GROOTENDORST, M. KeyBERT: Minimal keyword extraction with BERT. Zenodo, 2020. Disponível em: <https://doi.org/10.5281/zenodo.4461265>. Acesso em: 03 fev. 2025.
HAMMES, L.; FREITAS, L. Utilizando bertimbau para a classificação de emoções em português. In: Anais do XIII Simpósio Brasileiro de Tecnologia da Informação e da Linguagem Humana. Porto Alegre, RS, Brasil: SBC, 2021. p. 56–63. ISSN 0000-0000. Disponível em: <https://sol.sbc.org.br/index.php/stil/article/view/17784>. Acesso em: 06 fev. 2025.
IASULAITIS, S., VALEJO, A.D.B., VICARI, I., MESSIAS, G.H., GRECO, B.C, PERILLO, V.C. The Interfaces Twitter Elections Dataset: construction process and characteristics of Big Social Data during the 2022 presidential elections in Brazil. Plos One, p. 1-27, 2024. Acesso em: 06 fev. 2025.
JIANG, B. et al. Mechanisms and Attributes of Echo Chambers in Social Media. 2021.
MCPHERSON, M.; SMITH-LOVIN, L.; COOK, J. M. Birds of a feather: Homophily in social networks. Annual Review of Sociology, v. 27, n. 1, p. 415–444, 2001. Disponível em: <https://doi.org/10.1146/annurev.soc.27.1.415>.
NICKERSON, R. S. Confirmation bias: A ubiquitous phenomenon in many guises. Review of General Psychology, v. 2, n. 2, p. 175–220, 1998. Disponível em: <https://doi.org/10.1037/1089-2680.2.2.175>. Acesso em: 04 fev. 2025.
PARISER, E. The Filter Bubble: How the New Personalized Web Is Changing What We Read and How We Think. Penguin Publishing Group, 2011. ISBN 9781101515129. Disponível em: <https://books.google.com.br/books?id=wcalrOI1YbQC>.
REIMERS, N.; GUREVYCH, I. Sentence-bert: Sentence embeddings using siamese bert-networks. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2019. Disponível em: <http://arxiv.org/abs/1908.10084>. Acesso em: 05 fev. 2025.
ROSSETTI, G.; MILLI, L.; CAZABET, R. Cdlib: a python library to extract, compare and evaluate communities from complex networks. Applied Network Science, v. 4, n. 1, p. 52, Jul 2019. ISSN 2364-8228. Disponível em: <https://doi.org/10.1007/s41109-019-0165-9>. Acesso em: 06 fev. 2025.
ROSVALL, M.; BERGSTROM, C. T. Maps of random walks on complex networks reveal community structure. Proceedings of the National Academy of Sciences, v. 105, n. 4, p. 1118–1123, jan. 2008. ISSN 1091-6490. Disponível em: <http://dx.doi.org/10.1073/pnas.0706851105>.Acesso em: 05 fev. 2025.
TEAM, T. pandas development. pandas-dev/pandas: Pandas. Zenodo, 2024. Disponível em: <https://doi.org/10.5281/zenodo.10697587>. 04 fev. 2025.
TRAAG, V. A.; WALTMAN, L.; ECK, N. J. van. From louvain to leiden: guaranteeing well-connected communities. Scientific Reports, v. 9, n. 1, p. 5233, Mar 2019. ISSN 2045-2322. Disponível em: <https://doi.org/10.1038/s41598-019-41695-z>. Acesso em: 06 fev. 2025.
VICARIO, M. D. et al. The spreading of misinformation online. Proceedings of the National Academy of Sciences, v. 113, n. 3, p. 554–559, 2016. Disponível em: <https://www.pnas.org/doi/abs/10.1073/pnas.1517441113>. Acesso em: 06 fev. 2025.
Dataset
O conjunto de dados utilizado na pesquisa está disponível em:
● https://github.com/Interfaces-UFSCAR/ITED-Br
O código da coleta de dados está disponível em:
● https://github.com/Interfaces-UFSCAR/Codigo-Coleta-PLOS-ONE
Conformidade com os Termos de Uso do Twitter e da API do Twitter
Todas as etapas desta pesquisa envolveram atenção e cuidado com as regras do Twitter para o uso de seus dados. Os termos que foram acordados, quando as partes correspondentes envolvidas no estudo solicitaram o acesso de pesquisador, podem ser encontrados nos Termos de Uso do Twitter (e da API do Twitter) e no Contrato e Política do Desenvolvedor.
Neste contexto, Desenvolvedor se refere a qualquer pessoa que utilize os serviços ou dados do Twitter para coletar, transformar e/ou redistribuir conteúdo do Twitter em qualquer formato.
É possível obter uma cópia desses termos, em sua totalidade, utilizando serviços de arquivamento - dos quais um dos mais utilizados é o Internet Archive, com mais de bilhões de páginas da web arquivadas até o momento em que este texto foi escrito. Cópias desses termos também foram salvas localmente para referência, e ambas foram e serão usadas para dar suporte à conduta legal e ao aproveitamento dos frutos desta pesquisa.
Todos os dados foram coletados e armazenados em observância às regras do Twitter sobre proteção do usuário e segurança de dados, e assim permanecerão. Este estudo não faz uso nem exibe nenhuma informação sensível do usuário, e apenas fornece análises consistentes com as expectativas razoáveis de privacidade dos usuários do Twitter, incluindo apenas dados postados publicamente, o que também se aplica para o conjunto de dados resultante deste estudo.
Finalmente, é importante observar que todo o conteúdo fornecido a terceiros, de qualquer maneira, permanecerá sujeito aos mesmos acordos e políticas - e esforços serão feitos para garantir que todas as partes sejam informadas e concordem com estes termos e políticas - o que é necessário para a transferência compatível de dados do Twitter. Tais cuidados foram tomados na disponibilização dos dados no GitHub do grupo de pesquisas Interfaces.